1. Introduction
Autoencoders are an essential concept in deep learning, allowing models to automatically learn compressed representations of data without supervision. These networks have gained popularity due to their ability to extract meaningful features and reconstruct inputs with minimal loss. From image compression to anomaly detection, autoencoders power some of the most innovative AI applications. In this article, we’ll explore their architecture, types, use cases, advantages, and limitations.
In this article, we’ll explore the architecture, types, and applications of autoencoders, along with their advantages, limitations, and role in building smarter systems within deep learning and AI Development Services.

2. What Are Autoencoders?
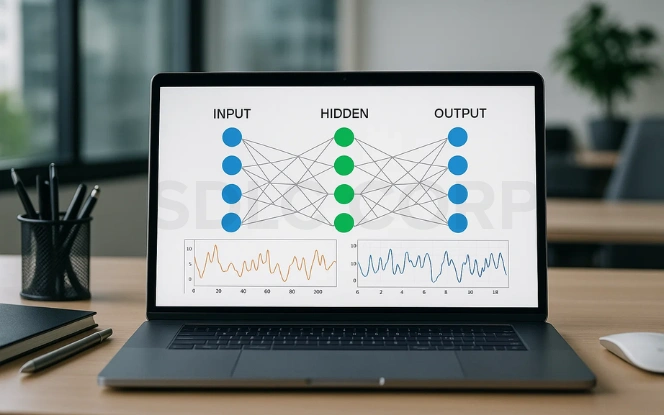
Autoencoders are a special class of unsupervised neural networks that aim to learn compressed, meaningful representations of input data. Instead of relying on labeled datasets, they learn by reconstructing their input, making them ideal for unsupervised learning tasks. These networks work by encoding the input into a lower-dimensional latent space (often referred to as the bottleneck) and then decoding it back to reconstruct the original data. This process forces the model to capture the most critical features of the data, which makes autoencoders highly effective for feature extraction, dimensionality reduction, anomaly detection, and data reconstruction.
Key components of an autoencoder:
- Encoder: Compresses the input into a compact latent representation, focusing on retaining only the most significant features.
- Decoder: Reconstructs the original input from the encoded representation, aiming to minimize the loss between the original and reconstructed data.
This structure allows autoencoders to filter out noise and redundancy, making them valuable in applications such as image denoising, text feature learning, and audio processing. Their ability to discover hidden structures within data also makes them a popular tool for AI development companies working on advanced deep learning solutions.
3. How Do Autoencoders Work?
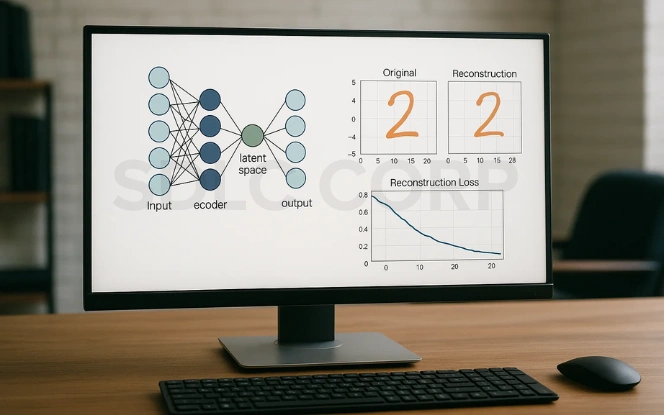
Autoencoders work by learning to minimize the difference between the input data and its reconstructed output. They achieve this by compressing the input into a latent representation and then reconstructing it as closely as possible. This process ensures that the model captures the most important features of the data while discarding unnecessary details.
The working steps of an autoencoder:
- Step 1: Input data is passed through the encoder, reducing it to a latent space representation.
- Step 2: The decoder reconstructs the data from this encoded representation.
- Step 3: A loss function (e.g., Mean Squared Error) calculates the reconstruction error.
- Step 4: Weights are updated through backpropagation to minimize this error.
Through this iterative training, autoencoders learn meaningful and compressed data patterns.
4. Key Features of Autoencoders

Autoencoders stand out because of their ability to learn complex patterns in data without human intervention. They are especially useful in scenarios where labeled data is scarce or unavailable. Unlike traditional dimensionality reduction methods like PCA, autoencoders can model nonlinear relationships and capture intricate details within data. This makes them a highly versatile tool in deep learning for multiple data formats like images, text, and audio.
Key features include:
- Unsupervised learning: Autoencoders do not require labeled data, making them ideal for tasks where collecting labels is expensive or impractical.
- Dimensionality reduction: They compress data into a smaller representation, similar to PCA, but with the added ability to capture complex, nonlinear relationships.
- Latent space learning: Autoencoders learn a compressed “hidden” representation of data, which can reveal underlying structures and features that are not easily visible.
- Flexibility: They can work with different data types images (for compression or denoising), text (for feature extraction), and audio (for noise reduction or synthesis).
5. Types of Autoencoders

Autoencoders are not one-size-fits-all; they come in various forms designed to meet different deep learning needs. Each type offers unique capabilities, from improving data quality to generating entirely new samples. This flexibility makes them suitable for tasks like image processing, anomaly detection, and even generative modeling.
Common types of autoencoders include:
- Vanilla Autoencoder: A basic encoder-decoder structure with fully connected layers, mainly used for simple dimensionality reduction tasks.
- Convolutional Autoencoder: Incorporates Convolutional Neural Networks (CNNs), making them excellent for image compression, denoising, and reconstruction tasks.
- Variational Autoencoder (VAE): Adds a probabilistic approach to encoding, enabling the generation of new, synthetic data samples similar to the training data.
- Denoising Autoencoder: Trained to remove noise from inputs, making them highly effective for image and audio restoration tasks.
- Sparse Autoencoder: Imposes sparsity constraints on neurons, ensuring only the most critical features are learned, which improves feature extraction.
- Contractive Autoencoder: Adds regularization to make encoded representations more robust to slight input variations, improving stability.
6. Applications of Autoencoders
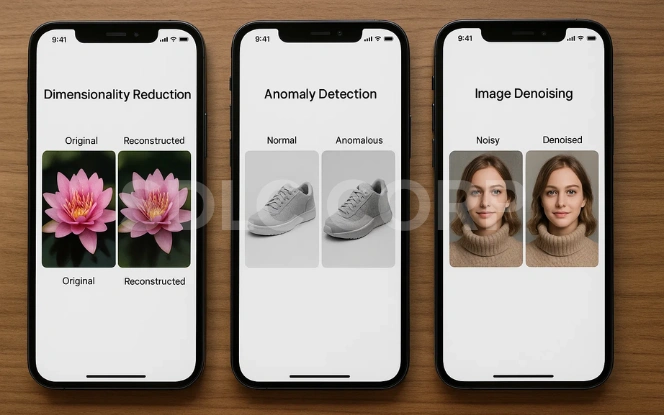
Autoencoders are widely used across industries because of their ability to learn meaningful representations of complex data. Their versatility makes them valuable in tasks ranging from improving data quality to generating new synthetic samples. Whether it’s compressing large files or detecting anomalies in financial transactions, autoencoders have proven to be a reliable deep learning tool for both research and real-world applications.
Key applications include:
- Image compression: Efficiently reduce image file sizes while maintaining visual quality, useful in storage and transmission.
- Anomaly detection: Identify irregular patterns in systems such as fraud detection, cybersecurity, or manufacturing defect detection.
- Denoising: Clean corrupted images, audio, or other signals, restoring them to near-original quality.
- Feature extraction: Generate compact, meaningful features that can enhance the performance of other machine learning models.
- Data generation: Variational Autoencoders (VAEs) can create synthetic data samples, beneficial for model training or simulations.
- Medical imaging: Improve the clarity of medical scans, perform segmentation, or detect abnormalities in imaging data.
7. Advantages of Autoencoders
| Advantage | Description |
|---|---|
| Learn data-specific features | Extract hidden, meaningful representations without requiring labeled data. |
| Reduce noise and improve quality | Denoise images, audio, or signals to enhance overall data quality. |
| Stackable for deep feature learning | Multiple autoencoders can be layered to learn complex, hierarchical features. |
| Nonlinear dimensionality reduction | Capture complex relationships beyond the capability of linear methods like PCA. |
Autoencoders offer several advantages that make them a valuable tool in deep learning. They can automatically learn meaningful, data-specific features without the need for labeled datasets, making them ideal for unsupervised tasks. Additionally, their ability to capture nonlinear patterns allows them to outperform traditional dimensionality reduction methods like PCA in many cases.
8. Limitations of Autoencoders

While autoencoders are powerful, they are not without challenges. Their performance depends heavily on the quality and quantity of training data, and in some cases, they can overfit, learning to memorize inputs instead of generalizing to unseen data. Additionally, their reconstructed outputs, especially for images, may lack sharpness, limiting their use in high-fidelity applications.
Key limitations include:
- Overfitting risk: Autoencoders may memorize training data instead of learning general patterns, reducing their real-world effectiveness.
- Blurry outputs: Reconstructions, particularly in image tasks, can lose sharp details and appear visually soft.
- Large dataset requirement: They require substantial training data for optimal performance, making them resource-intensive.
- Not ideal for direct classification: Best suited for feature extraction or preprocessing, but not for tasks like direct image or text classification.
9. Future of Autoencoders
The future of autoencoders looks promising as they continue to evolve beyond traditional reconstruction tasks. They are expected to integrate more deeply with generative AI, enabling models to produce highly realistic synthetic data for various applications. Additionally, their combination with reinforcement learning, supervised learning techniques, and self-supervised learning approaches could unlock new possibilities in autonomous systems and adaptive AI. Emerging techniques like transformers and diffusion models are also being paired with autoencoders, paving the way for more robust, scalable, and versatile architectures. This positions autoencoders as a cornerstone of next-generation AI systems.

10. Conclusion
Autoencoders are more than just a tool for data compression they are a powerful gateway into understanding how machines can learn meaningful patterns from raw data. Whether applied to images, text, or signals, these networks provide endless opportunities for feature learning, data reconstruction, and innovation in AI applications. As deep learning continues to advance, autoencoders will remain a cornerstone technology, helping every AI development company build smarter, more efficient, and versatile AI models for the future.
FAQs
1. What is an autoencoder in deep learning?
An autoencoder is a type of neural network that learns to compress input data into a lower-dimensional representation (encoding) and then reconstruct it back to its original form (decoding). It is widely used for dimensionality reduction, feature learning, and data reconstruction in deep learning.
2. How do autoencoders differ from other dimensionality reduction techniques like PCA?
Unlike PCA, which only performs linear transformations, autoencoders can capture complex, nonlinear patterns in data. This makes them more powerful for tasks like image processing, anomaly detection, and generative modeling.
3. What are the main applications of autoencoders?
Autoencoders are used in image compression, denoising, anomaly detection, feature extraction, data generation (via Variational Autoencoders), and medical imaging. They are also a valuable tool for AI development companies building advanced deep learning solutions.
4. What are the limitations of autoencoders?
Some key limitations include the risk of overfitting, blurry reconstructions for images, and the requirement for large datasets to achieve optimal performance. They also are not designed for direct classification tasks, working best as feature extractors.
5. How do Variational Autoencoders (VAEs) differ from regular autoencoders?
Variational Autoencoders introduce a probabilistic approach, allowing them to generate new, synthetic data samples. This makes VAEs highly popular in generative AI and creative applications like image and text generation.
6. Are autoencoders suitable for real-world AI projects?
Yes. Autoencoders are widely used in real-world AI development, from fraud detection to data compression and healthcare imaging. Partnering with an AI development company can help you implement customized autoencoder solutions tailored to your business needs.