Introduction
Ever had that moment when your AI just gets what you’re asking for without any examples? That’s not magic it’s-zero-shot learning at work, and it’s changing everything about how machines understand us. Machine learning used to be like teaching a toddler: show them the same thing repeatedly until they finally get it. But zero-shot learning insights are flipping the script entirely. What if I told you that today’s AI can classify objects it’s never seen before, translate languages it wasn’t explicitly trained on, and generate content in styles it’s never encountered? That’s the power of transferable knowledge and it’s reshaping the future of AI development Solutions.

1. Fundamentals of Zero-Shot Learning
1.1 Key concepts and definitions
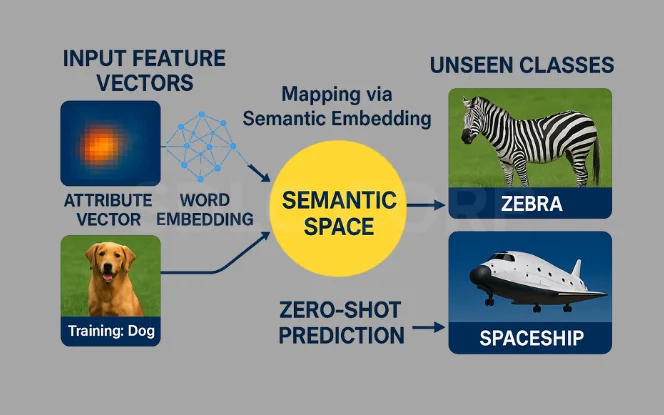
Definition: Zero-shot learning (ZSL) is a machine learning approach where models can make predictions about unseen classes without any prior examples during training.
Core Principle: ZSL relies on transferable knowledge, learning general semantic attributes that can apply to new categories.
How It Works: The model connects:
Semantic attributes (e.g., “has trunk,” “is purple”)
Visual features (e.g., shape, color, structure)
to infer new classes.
Goal: Enable recognition of novel categories without needing specific labeled training data for them.
1.2 How Zero-Shot Learning Differs from Other Machine Learning Approaches
Traditional machine learning is like studying for a specific test – you know exactly what questions will be asked.
Zero-shot learning? That’s more like preparing for anything life might throw at you.
| Learning Paradigm | Training Data | Test Classes | Key Difference |
|---|---|---|---|
| Traditional ML | Classes A, B, C | Classes A, B, C | Seen classes only |
| Few-shot learning | Classes A, B, C | Classes D, E (with a few examples) | Limited examples of new classes |
| Zero-shot learning | Classes A, B, C | Classes D, E (no examples) | No examples of new classes |
The magic happens through semantic spaces – while traditional models can only recognize what they’ve been explicitly trained on, zero-shot models can make connections between seen and unseen concepts.
1.3 Historical development and breakthroughs
2008–2009: Early Exploration
Researchers began exploring more flexible machine learning models.
Initial focus was on making models generalize beyond their training data.
2013: Introduction of Word Embeddings
Major breakthrough with the use of word embeddings (e.g., Word2Vec).
Enabled linking linguistic concepts (like class names and attributes) to visual features.
Bridged the gap between language and image understanding.
2017: Generalized Zero-Shot Learning (GZSL)
Emergence of frameworks capable of recognizing both seen and unseen classes.
Marked a shift from theoretical models to more real-world applicable systems.
Post-2018: Rise of Large Language and Vision-Language Models
Introduction of GPT and CLIP revolutionized ZSL.
Demonstrated powerful cross-domain zero-shot capabilities (text, image, multimodal).
Represented a massive leap forward in the field’s practical impact.
1.4 Core technical mechanisms
So how does this magic actually work?
Zero-shot learning typically relies on three key mechanisms:
Attribute-Based Learning – Models learn visual attributes (e.g., “striped,” “has wings”) that can be combined in new ways.
Embedding Spaces – By mapping both images and class descriptions into the same vector space, models can measure similarity between unseen classes and known visual features.
Knowledge Graphs – Some approaches use structured knowledge to understand relationships between concepts, helping models make logical leaps to new classes.
The cornerstone is finding common ground between what the model already knows and what it needs to predict. Modern approaches often use transformers to create rich semantic spaces where new concepts can be understood through their relationship to familiar ones.
2. Real-World Applications
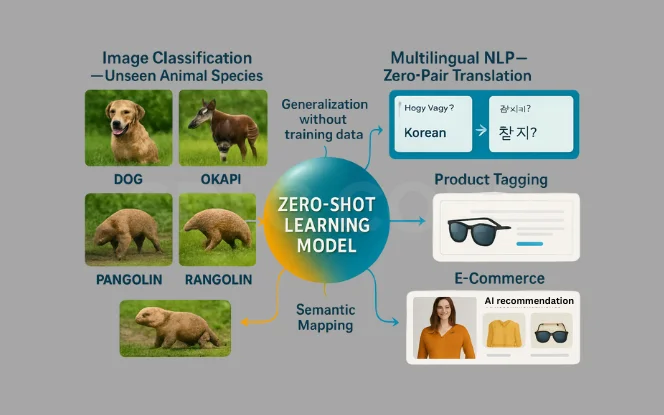
2.1 Natural Language Processing Implementation
Flexibility
Zero-shot learning allows models to perform NLP tasks they’ve never been trained on directly.
Example – GPT Models:
Can translate, summarize, and answer questions without task-specific training.
Can classify customer feedback into new categories without labeled examples.
Industry Use:
Used in chatbots to handle unexpected user queries effectively.
Prompt engineering is key designing smart instructions to guide model behavior in real time.
2.2 Computer Vision Use Cases
CLIP by OpenAI
Learns the relationship between images and text descriptions.
Identifies objects it has never seen before.
Applications:
Retail: Recognizes new products without retraining.
Security: Detects unusual activities without needing prior examples.
Museums: Automatically catalogs artifacts across eras without specialized models.
2.3 Healthcare Diagnostics
Radiology
Identifies rare conditions even with scarce data.
Spots unusual patterns in scans that hint at diseases not seen during training.
Rare Disease Diagnosis
Helps diagnose orphan diseases without large datasets.
Drug Discovery
Predicts compound–protein interactions using zero-shot inference.
Speeds up early-stage drug screening.
2.4 Financial Forecasting
Market Analysis
Detects anomalies and trends in assets with little historical data.
Trading algorithms adapt to new conditions using knowledge from familiar patterns.
Fraud Detection
Recognizes new scam tactics by identifying conceptual similarities to past fraud.
Enhances adaptability against ever-evolving threats.
2.5 Recommendation Systems
Cold Start Problem Solved
Recommends new content (e.g., shows, products) even without user interaction history.
Cross-Domain Recommendations
Suggests books based on movie preferences or music from art interests.
Uses abstract feature matching, not just historical patterns.
E-Commerce Use
Promotes new product categories through semantic similarities, enhancing discovery and personalization.
3. Advantages of Zero-Shot Learning
3.1 Reducing dependency on labeled data
Problem with Traditional ML
Requires large volumes of labeled data.
Manual annotation is time-consuming and expensive.
Zero-Shot Solution
Models can recognize new classes without needing labeled examples.
Example: If a model knows “zebra” and “horse,” it can infer what a mule is.
Key Benefits
Saves hundreds of hours on data labeling.
Speeds up model development and deployment.
Frees data scientists to focus on core challenges instead of annotation tasks.
3.2 Scalability across domains
Traditional Limitation
Models trained in one domain (e.g., medical) struggle when applied to another (e.g., legal).
Zero-Shot Flexibility
One model can transfer knowledge across different domains without retraining.
Example: A model trained on medical text can handle legal documents.
Key Benefits
Enables cross-domain deployment.
Reduces need for domain-specific custom models.
Delivers significant cost savings and development efficiency.
3.3 Adaptability to new tasks
Traditional Constraint
New tasks typically require new models or retraining.
Zero-Shot Advantage
Existing models can be reused for entirely new tasks.
Example: A product categorization model can be repurposed for sentiment analysis.
Key Benefits
Supports faster innovation cycles.
Lowers maintenance and retraining costs.
Makes AI systems more agile and responsive to changing business needs.
4. Challenges and Limitations
4.1 Performance Trade-Offs vs. Supervised Learning
Zero-shot learning is cool, but let’s not kid ourselves it comes with some serious trade-offs when compared to traditional supervised approaches.The accuracy gap is real. When you have tons of labeled data, supervised models will almost always outperform zero-shot alternatives. It’s like comparing a rookie who’s never seen a basketball game to LeBron James.
The rookie might surprise you occasionally, but consistency? Not even close.The computational demands hit differently too. Zero-shot models need to be much larger to capture those cross-domain relationships. We’re talking bigger models, more parameters, and heavier inference costs.
Comparison: Supervised Learning vs. Zero-Shot Learning
| Aspect | Supervised Learning | Zero-Shot Learning |
|---|---|---|
| Accuracy | Higher on in-domain tasks | Lower but more flexible |
| Data Requirements | Lots of labeled examples | No task-specific labels |
| Model Size | Can be relatively compact | Typically much larger |
| Inference Speed | Usually faster | Often slower |
4.2 Domain adaptation difficulties
Semantic Gap
Large differences between source and target vocabulary or concepts can reduce model effectiveness.
Example: A model trained on product reviews may perform poorly on medical texts due to domain-specific terminology.
Distribution Shift
Changes in data style, format, or quality can cause performance drops.
Example: A model trained on studio-quality images may fail on grainy surveillance footage.
Key Challenge
Zero-shot learning struggles when the source and target domains are too dissimilar.
4.3 Model interpretability issues
Black-Box Nature
Zero-shot models operate through complex and opaque mechanisms, making it difficult to explain predictions.
Example: It’s often unclear why a specific label or output was chosen.
Consequences of Poor Interpretability
Debugging becomes time-consuming.
Performance issues are harder to trace and fix.
Stakeholder trust is harder to earn due to lack of clarity.
4.4 Bias and Fairness Considerations
Bias Inheritance from Training Data
Zero-shot models are often trained on large-scale, web-scraped datasets.
These datasets contain societal biases (gender, race, culture, etc.), which the models absorb.
Unpredictable Bias Manifestation
Biases may not be obvious during initial testing.
A model that seems fair in one domain may behave unfairly in another (e.g., biased job recommendations in different cultures).
Evaluation Challenges
It’s impossible to test fairness across all future use cases or domains.
The open-ended nature of zero-shot tasks makes comprehensive bias auditing infeasible.
Key Concern
Bias mitigation is especially difficult due to:
Lack of task-specific data
Diverse applications
Opaque decision-making processes
5. Building Effective Zero-Shot Models
5.1 Architectural Considerations
Different Mindset Required
Designing zero-shot models requires a shift from traditional supervised architectures.
You’re not just following a “recipe” you’re building systems to generalize beyond seen data.
Backbone Model is Critical
Transformer architectures are highly effective due to their ability to capture semantic relationships.
They excel at encoding complex patterns between inputs and descriptions.
Shared Embedding Space
Success in zero-shot learning depends on creating a common semantic space where both input data and unseen class labels coexist meaningfully.
Dual-Encoder Architectures
One encoder processes input data (e.g., images, text).
The second encoder handles class descriptions or prompts.
These outputs are compared in the shared embedding space to find semantic matches.
Key Design Goal
Enable the model to measure similarity between what it knows (seen classes) and what it hasn’t seen (unseen classes) using learned representations.
5.2 Feature representation strategies
The secret sauce of zero-shot learning? How you represent your features.
Good feature spaces need to be:
- Dense with meaningful information
- Transferable across domains
- Semantically organized
Visual-semantic embeddings are game-changers. They map images and text into the same vector space, letting your model connect dots it’s never explicitly seen before.
Try this: instead of single-point embeddings, work with distributional representations. They capture uncertainty better, which is gold when you’re asking your model to recognize stuff it’s never seen.
5.3 Prompt engineering techniques
- Chain-of-thought prompting (walk the model through reasoning steps)
- Few-shot examples within your zero-shot prompt (yes, that’s a thing)
- Contrastive prompting (what it is vs. what it isn’t) The magic happens when you provide context without giving away the answer. That’s the balancing act.
5.4 Model selection criteria
Picking the right model isn’t about chasing state-of-the-art benchmarks.
Focus on:
Generalization capabilities over raw performance
Robustness to distribution shifts
Calibration – knowing when it doesn’t know
Inference efficiency – because production environments aren’t research playgrounds
The best zero-shot models are often not the ones with the most parameters, but those trained on diverse data with thoughtful objectives.
6. Future Directions
6.1 Emerging Research Trends
Robustness to Distribution Shifts
Current research focuses on making zero-shot models resilient to unfamiliar input data.
Goal: Improve generalization when test data significantly differs from training data.
Neuro-Symbolic Integration
Combines neural networks (pattern recognition) with symbolic AI (logical reasoning).
Enables models to handle novel, complex scenarios with improved reasoning.
Self-Supervised Learning
Models learn from unlabeled data to build stronger internal representations.
Enhances flexibility and transferability in zero-shot settings
6.2 Integration with Few-Shot Learning
Blending Zero-Shot and Few-Shot
Systems start with zero-shot learning but adapt when given a few labeled examples.
Creates a continuum rather than strict boundaries between learning paradigms.
Adaptive Shot Frameworks
Models self-determine how many examples are needed based on task complexity.
Simple tasks may require zero examples, while complex tasks trigger few-shot adaptation.
6.3 Multimodal Zero-Shot Approaches
Cross-Modal Capabilities
Models link text, images, audio, and video without task-specific training.
Examples: CLIP and DALL·E demonstrate effective text–image understanding.
Toward Sensory Generalization
Future models aim to handle touch, spatial awareness, and physical interaction.
Goal: Robots and systems that can act based on descriptions alone.
6.4 Edge Computing Implementations
On-Device Intelligence
Zero-shot models are compressed and distilled to run on phones, IoT devices, and embedded systems.
Enables offline inference for enhanced privacy and reduced cloud dependency.
Efficiency Innovations
Utilizes techniques like quantization, pruning, and lightweight architectures.
Allows complex AI models to run efficiently in resource-constrained environments.
Example Use Case
A smart home device that can recognize unprogrammed behaviors or objects without needing cloud access.
7. Tools Supporting Zero-Shot Learning
To build powerful Zero-Shot Learning (ZSL) models, developers often rely on specialized tools that enable semantic understanding, transfer learning, and embedding comparison. Here are the top tools supporting ZSL:
7.1 Hugging Face Transformers
Offers ready-to-use pipelines like zero shot classification.
Supports a variety of models such as BART, RoBERTa, and GPT.
Excellent for text-based zero-shot tasks with minimal code.
7.2 OpenAI CLIP
Bridges vision and language by embedding both into a shared space.
Enables zero-shot image classification using textual prompts.
Popular in visual recognition and multi-modal applications.
7.3 Sentence Transformers
Provides pre-trained models for generating sentence embeddings.
Great for zero-shot classification through semantic similarity.
Lightweight and fast for real-time inference use cases.
7.4 AllenNLP
A research-friendly framework tailored for NLP tasks.
Supports quick prototyping of zero-shot models using pre-trained encoders.
Ideal for explainable and interpretable NLP workflows.
7.5 LangChain
Enables zero-shot reasoning and decision-making via prompt engineering.
Useful for chaining multiple tasks using large language models (LLMs).
No-code and low-code integrations make it developer-friendly.

Conclusion
Zero-shot learning is a powerful machine learning approach that enables models to make predictions about unseen classes without needing labeled examples. By leveraging semantic relationships and knowledge transfer, it opens doors to tasks like language translation, rare disease diagnosis, and wildlife monitoring especially where labeled data is limited. Visit us at AI development services to learn how your organization can benefit.
Its key strengths are flexibility and efficiency, but success relies on:
Well-designed semantic spaces
Strong feature extraction
Clear evaluation strategies
FAQs
Q1. What is zero-shot learning in simple terms?
Zero-shot learning (ZSL) is a machine learning technique where a model can make predictions about new, unseen data classes without having been explicitly trained on them. It uses semantic understanding or feature relationships to generalize knowledge from known to unknown categories.
Q2. How is zero-shot learning different from traditional machine learning?
Traditional machine learning requires labeled training data for every class it needs to recognize. Zero-shot learning, on the other hand, can classify or understand new classes based on their semantic descriptions or relationships to known concepts, without needing specific training examples.
Q3. Can zero-shot learning completely replace supervised learning?
Not entirely. While ZSL is powerful for generalization and low-data situations, supervised learning still delivers higher accuracy when large amounts of labeled data are available. ZSL is more useful when labeling is expensive or impractical.
Q4. What are real-world examples of zero-shot learning?
Examples include:
- GPT models answering questions they weren’t specifically trained for.
- CLIP identifying new objects using image-text associations.
- Medical imaging systems detecting rare diseases.
- E-commerce platforms recommending new products without historical data.
Q5. What are the main challenges of zero-shot learning?
- Lower accuracy compared to supervised models
- Semantic gaps between training and testing data
- High model complexity and computational demands
- Difficulty in interpretation and debugging
- Potential biases inherited from training data
Q6. What role do prompts play in zero-shot learning?
Prompts are instructions or questions that guide zero-shot models like GPT to perform specific tasks. Effective prompt engineering can drastically improve the performance of zero-shot models in NLP and beyond.
Q7. How does zero-shot learning work in computer vision?
In vision, zero-shot learning often uses shared embedding spaces. Both image features and class descriptions are projected into a common space, allowing the model to compare and match unseen image classes with their semantic descriptions.
Q8. What is the difference between zero-shot and few-shot learning?
- Zero-shot: No examples of the new class during training.
- Few-shot: Very limited examples (e.g., 1–5) are provided for new classes. Few-shot learning is useful when minimal but some labeled data is available.
Q9. Are zero-shot models suitable for deployment on edge devices?
Yes, although it’s challenging. Through techniques like model compression, quantization, and distillation, zero-shot learning is being brought to edge devices for real-time, offline decision-making, particularly in smart home and IoT environments.
Q10. What tools or frameworks support zero-shot learning?
Some popular tools and frameworks include:
- OpenAI’s GPT and CLIP
- Hugging Face Transformers
- Google’s T5 and PaLM
- Facebook’s XLM-R and DINO
These provide pre-trained models with zero-shot capabilities for NLP, vision, and cross-modal tasks.