
Introduction
Synthetic data generation is reshaping modern business by fueling artificial intelligence (AI), analytics, and digital transformation. Real-world data often creates hurdles: it is expensive to collect, limited in scope, and bound by strict privacy regulations. To overcome these challenges, enterprises are increasingly turning to synthetic data as a safer and more scalable alternative.
There are several ways synthetic data generation supports innovation across industries, from healthcare and finance to autonomous vehicles and retail. It enables companies to build reliable models, test new ideas, and stay compliant with privacy standards. This article explores the concept, benefits, and practical applications of synthetic data generation to help you understand why it is becoming a strategic asset for businesses worldwide.

What Is Synthetic Data & Why It Matters
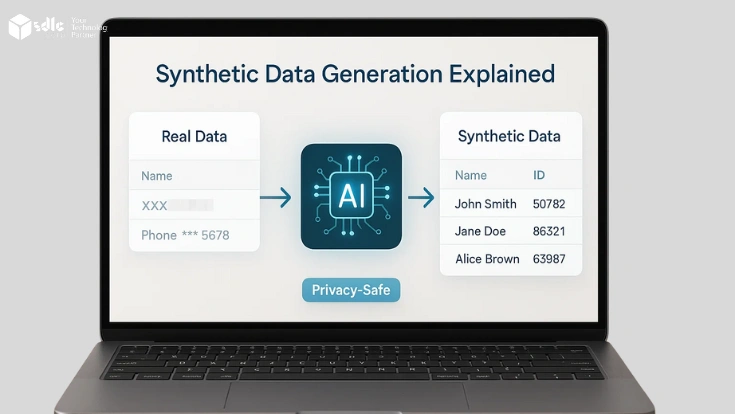
Synthetic data generation refers to information created by algorithms rather than collected directly from people or physical systems. In contrast, anonymized datasets may still reveal personal details because they are derived from real records. However, synthetic datasets are built from scratch while still maintaining the same statistical qualities as real data. Therefore, they become highly useful for analysis, training, and modeling across industries. Moreover, since they contain no actual identifiers, they provide stronger privacy protection for organizations.
Why Synthetic Data Is Essential
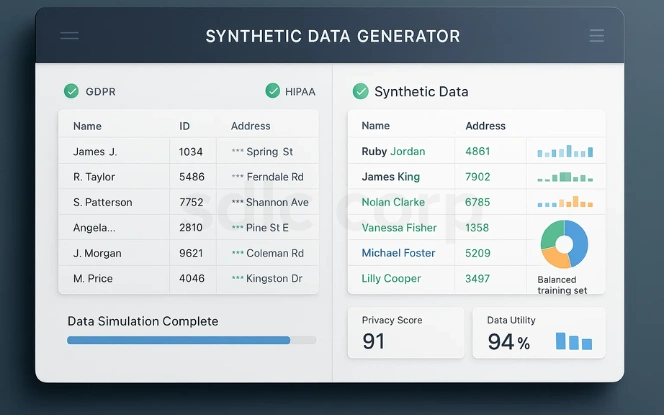
Privacy and Compliance: Meets regulations like GDPR, HIPAA, and CCPA by ensuring no link to real individuals.
Cost Savings: Cuts expenses tied to surveys, sensors, or manual data collection.
Speed of Innovation: Provides immediate datasets for rapid prototyping and scaling AI solutions.
Balanced Training Sets: Addresses class imbalances for cases like fraud detection or rare disease modeling.
Safe Collaboration: Enables secure data sharing across borders and industries without risking sensitive details.
Key Techniques & Methods of Synthetic Data Generation
Different methods suit different industries and use cases. Below are the most widely used approaches.
Random & Simulation-Based Generation
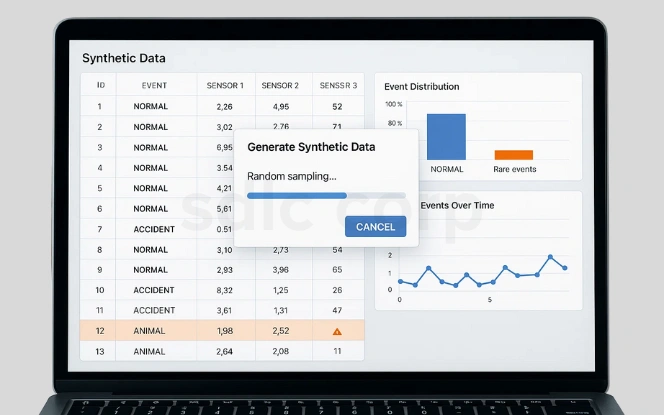
Early methods create synthetic values through random sampling or simulations.
Example: Autonomous vehicles are trained in virtual simulations that model traffic, weather, and unexpected hazards.
Strength: Captures rare edge cases that may not occur often in real data.
Weakness: There is a risk of oversimplification because models may fail to reflect complex real-world behaviors. As a result, organizations could make inaccurate assumptions. Moreover, such gaps can reduce the reliability of decisions and limit practical applications.
Rule-Based Generation
This method applies business logic or domain-specific rules to generate structured data.
Example: Financial institutions simulate transactions by applying constraints such as withdrawal limits and timestamps. In addition, they may include location data or spending patterns to reflect realistic scenarios. As a result, the generated datasets become more reliable for testing fraud detection systems.
Strength: Ensures logical consistency and domain accuracy.
Weakness: Can be rigid, failing to reflect natural variations in human behavior.
Generative Models (AI-Based)
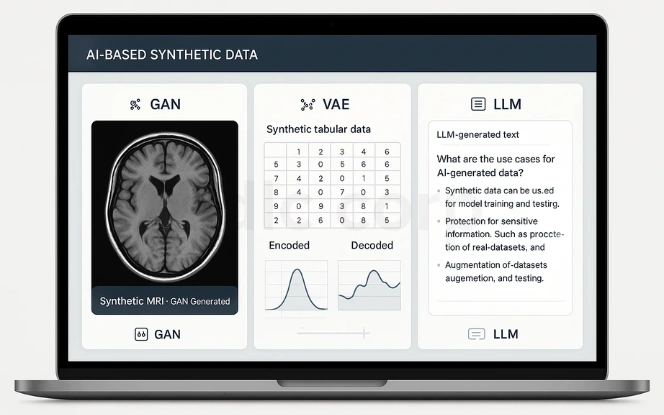
AI has elevated synthetic data quality through deep learning.
Generative Adversarial Networks (GANs): Competing networks generate highly realistic samples.
Variational Autoencoders (VAEs): Encode and decode patterns to create new synthetic records.
Large Language Models (LLMs): Produce synthetic text data for chatbots, FAQs, or documentation.
Example: Hospitals generate synthetic MRI scans with GANs to train diagnostic AI without exposing patient records.
Strength: Produces realistic structured, unstructured, and image-based data.
Weakness: Requires large computational resources and expert oversight.
Entity Cloning & Data Masking
Entity cloning copies dataset structures but replaces details with artificial values. In contrast, data masking hides sensitive identifiers while still keeping the format intact. Therefore, both methods protect privacy, yet they differ in how much original information remains.
Example: Telecom providers test billing systems with masked customer records.
Strength: Preserves realism and compliance.
Weakness: Synthetic data is still dependent on original data structures. As a result, its flexibility may be limited in certain use cases. Moreover, reliance on existing formats can restrict innovation when designing entirely new systems.
Hybrid Approaches
Organizations often combine methods. For instance, simulation-based environments enriched with GAN-generated outputs yield scalable, realistic datasets. Moreover, these combinations improve accuracy across different scenarios. As a result, businesses gain more reliable insights while reducing dependence on limited real-world data.
Evaluating the Quality of Synthetic Data
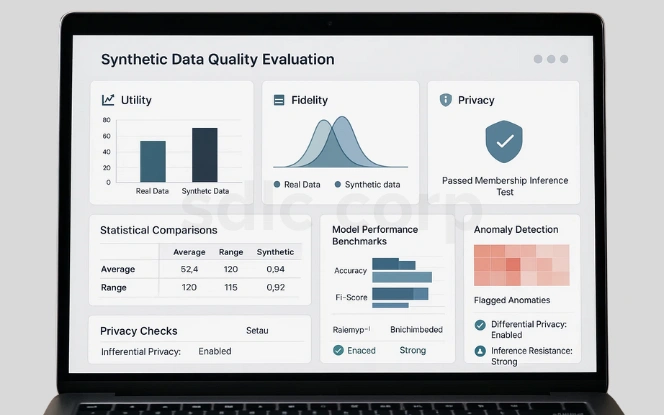
High-quality synthetic data is useful, realistic, and privacy-safe. Organizations measure it through three lenses:
Utility: Can models trained on synthetic datasets perform as effectively as those trained on real data?
Fidelity: Do the statistical distributions and correlations match real datasets?
Privacy: Can synthetic data resist reverse engineering attempts?
Evaluation Methods
Synthetic data must be validated to ensure it is reliable, realistic, and privacy-safe. Organizations use several evaluation techniques to confirm its quality before deployment.
Statistical Comparisons: Match averages, ranges, and correlations against real-world datasets.
Model Performance Benchmarks: Compare AI trained on synthetic vs. real datasets.
Anomaly Detection: Flag outliers that indicate unrealistic records.
Privacy Checks: Apply differential privacy or membership inference tests to confirm safety.
Use Cases Across Industries
Software Testing
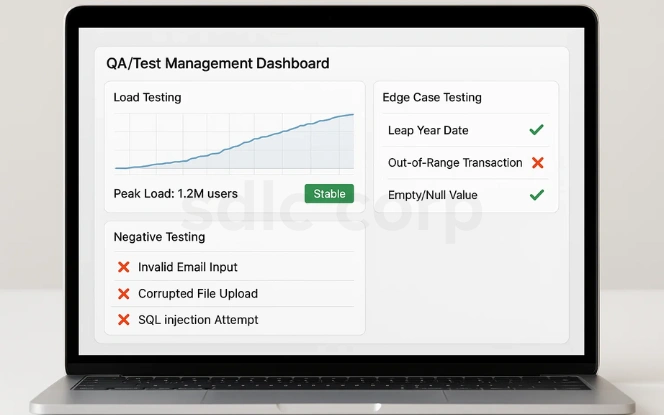
Synthetic data plays a crucial role in software testing by simulating conditions that may be hard to replicate with real users. It helps ensure systems are resilient, scalable, and secure.
Load Testing: Simulate millions of synthetic users to test platform scalability. This ensures the system performs reliably under peak usage conditions.
Negative Testing: Insert invalid or corrupted inputs to find vulnerabilities. It helps identify weak points that could cause failures in production.
Edge Case Testing: Model unusual scenarios rarely captured in production datasets. These tests prepare applications to handle unexpected events effectively.
Machine Learning & AI
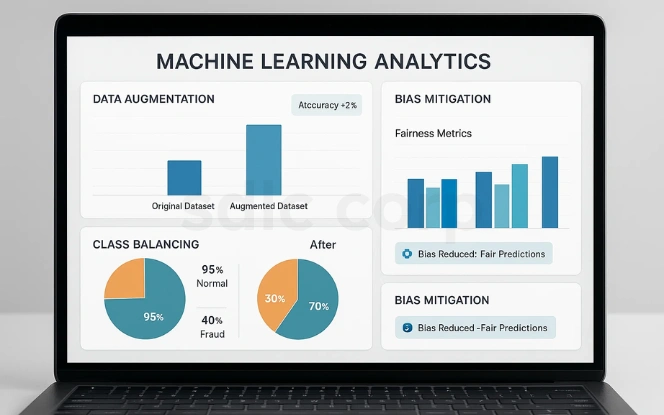
AI models depend on large, balanced, and diverse datasets. Synthetic data fills gaps, improves fairness, and reduces risks of bias in machine learning outcomes.
Data Augmentation: Expands datasets to improve model performance. This boosts accuracy, especially when real data is scarce.
Class Balancing: Generates rare class instances, such as fraudulent transactions. Balanced training data ensures better detection of minority cases.
Bias Mitigation: Creates diverse data samples to reduce skewed predictions. This leads to more ethical and trustworthy AI systems.
Read more- Introduction to Machine Learning
Privacy-Compliant Data Sharing
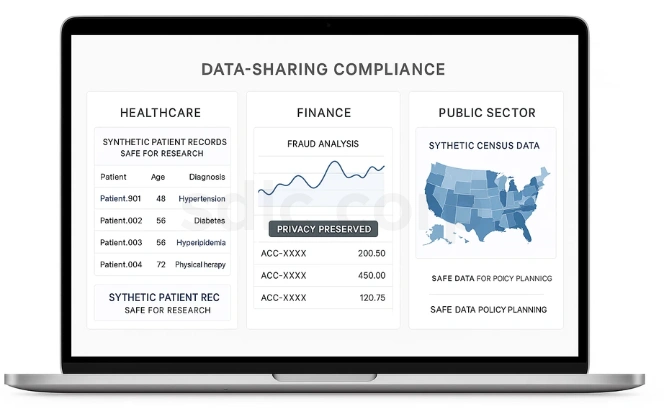
Synthetic datasets enable organizations to share information safely across sectors without violating privacy regulations. This promotes collaboration while maintaining compliance.
Healthcare: Provide synthetic patient records for safe research collaboration. This accelerates medical research without exposing sensitive details.
Finance: Share synthetic banking datasets for fraud analysis across institutions. It enhances security while protecting customer privacy.
Public Sector: Use synthetic census data for urban planning without exposing citizens. This helps governments design better policies responsibly.
Explore more – Generative AI for Healthcare
Challenges & Pitfalls
While synthetic data offers many benefits, organizations must be aware of its limitations. Addressing these challenges ensures its safe and effective use.
Technical Complexity: Requires advanced knowledge of AI and domain expertise. Without expertise, datasets may be inaccurate or misleading.
Bias Risk: Poorly designed models may replicate existing dataset biases. This can reinforce unfair outcomes in AI systems.
Validation Gaps: “Realism” is difficult to measure objectively. Weak validation can reduce trust in synthetic datasets.
Compute Demands: Training GANs or VAEs often requires costly GPUs. High resource needs may limit adoption for smaller firms.
Unclear Regulations: Global standards on synthetic data usage are still evolving. Lack of guidance creates uncertainty for compliance teams.
Best Practices for Synthetic Data Generation
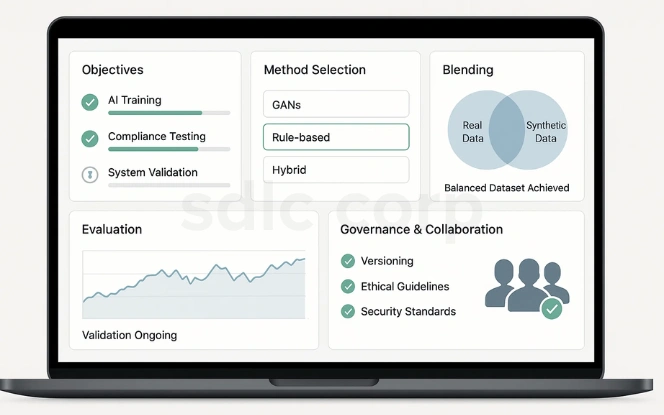
Adopting synthetic data requires clear planning and governance. Following best practices ensures it delivers value without introducing unnecessary risks.
Define Clear Objectives: Identify goals such as AI training, compliance testing, or system validation. Clear targets guide the choice of generation methods.
Select the Right Method: Match techniques (GANs, rule-based, or hybrid) to your use case. Each method has unique strengths and trade-offs.
Blend Real and Synthetic Data: Hybrid approaches often yield stronger, more balanced datasets. This ensures both realism and scalability.
Perform Continuous Evaluation: Regularly apply statistical and model benchmarks. Ongoing validation keeps synthetic data relevant and reliable.
Maintain Governance: Track versions, apply ethical guidelines, and enforce security standards. Strong governance ensures accountability and trust.
Collaborate with Experts: Involve domain specialists to reduce unrealistic outcomes. Expert input improves dataset quality and industry relevance.

Conclusion
Synthetic data is transforming the way organizations collect, manage, and share information. By combining AI-driven techniques such as GANs with rule-based and simulation approaches, businesses gain access to scalable, privacy-safe, and cost-effective datasets. Industries like healthcare, finance, automotive, and government are already applying synthetic data in daily operations, making it a critical driver of digital transformation.
At the same time, challenges such as bias, validation gaps, and evolving regulations remain. To address these effectively, many organizations choose to hire AI developers who bring the expertise needed to design reliable systems, maintain governance, and apply best practices. Over the next decade, synthetic data will shift from emerging technology to mainstream adoption, and those who invest early will secure long-term advantages in AI innovation, compliance, and collaboration.
Related Blogs:-
FAQ'S
What is synthetic data in simple words?
Synthetic data is artificially generated information that looks and behaves like real data but is not linked to any real person, transaction, or event. It is created using algorithms, simulations, or AI models to mimic the patterns, relationships, and statistical properties of real datasets. This makes it useful for testing, training, and research without exposing sensitive information.
Why is synthetic data important?
Synthetic data is important because it solves three major challenges businesses face today:
- Privacy compliance – It protects individuals’ personal information and helps companies comply with GDPR, HIPAA, and other data protection laws.
- Cost and efficiency – It reduces the time and expense of collecting, cleaning, and labeling large-scale real datasets.
- Innovation and scalability – It allows organizations to test new ideas, simulate rare scenarios, and train AI models even when real data is limited or unavailable.
What are the main techniques of generating synthetic data?
The most widely used synthetic data generation techniques include:
- Generative Adversarial Networks (GANs) – Two neural networks compete to produce highly realistic data.
- Variational Autoencoders (VAEs) – Encode and decode data to create new, similar samples.
- Rule-based generation – Uses business logic and domain rules to create structured data.
- Simulations – Creates synthetic data by modeling real-world environments, such as autonomous driving simulations.
- Entity cloning & masking – Replicates data structures while masking or replacing sensitive details.
Hybrid approaches – Combine multiple techniques for higher accuracy, diversity, and privacy.
Which industries benefit most from synthetic data?
Several industries rely on synthetic data to overcome challenges of privacy, scarcity, and cost:
- Healthcare – Generating synthetic patient records, diagnostic images, or clinical trial datasets.
- Finance – Simulating transactions for fraud detection, risk modeling, and stress testing.
- Telecom – Stress-testing networks with millions of synthetic call records.
- Automotive – Training autonomous vehicles in virtual environments with rare driving scenarios.
- Retail & E-commerce – Modeling consumer behavior, shopping trends, and personalized recommendations.
- Government & Public Sector – Creating synthetic census or population data for secure research and policy-making.
Can synthetic data replace real data completely?
Not entirely. While synthetic data is extremely useful, real-world data is still necessary for validation, benchmarking, and ensuring models reflect reality. The best practice is to use a hybrid approach, combining real and synthetic data:
- Synthetic data fills gaps, balances classes, and ensures privacy.
- Real data validates accuracy and grounds AI models in reality.
This combination delivers the best of both worlds—privacy, scalability, and compliance from synthetic data, alongside authenticity and reliability from real-world datasets.












