Introduction
Instruction tuning is a key technique that helps large language models (LLMs) like ChatGPT and LLaMA understand and follow natural human instructions. It goes beyond fine-tuning and prompt engineering by training models to respond accurately and helpfully to user commands.As AI becomes more integrated into daily tasks like writing emails or answering medical queries ensuring alignment with human intent is crucial for safety and usefulness.To build custom, instruction-tuned AI solutions, explore AI Development Solutions.

1. What is Instruction Tuning
Instruction tuning is a specific type of model training that involves teaching AI models to better follow human-written instructions.
Definition and Origin
Definition: Instruction tuning is a form of supervised fine-tuning that uses instruction-response pairs to guide the model’s behavior.
Origin: This method was introduced to improve how pre-trained language models interpret and act on human intent. It gained prominence with models like T5 and InstructGPT, where researchers observed that explicitly training models on diverse instructions led to more helpful and aligned outputs.
Core Objectives
Align AI output with natural language instructions
Ensures the model responds in ways that match how humans phrase requests.
Enhance model usability and responsiveness
Makes the model more practical for real-world applications like chatbots, virtual assistants, and content generation.
Reduce ambiguity in responses
Encourages models to provide clearer, more direct answers by learning the structure and tone of effective instruction-following.
Difference from Fine-Tuning
Fine-Tuning:
Focuses on adapting a model to perform well on a specific task or dataset (e.g., sentiment analysis, summarization).
Often requires labeled data for that task and does not necessarily improve instruction-following behavior across other tasks.
Instruction Tuning:
Trains the model using a broad set of instruction-response examples across many domains.
Helps the model generalize better across tasks by learning how to follow instructions, not just what to output.
2. How Instruction Tuning Works
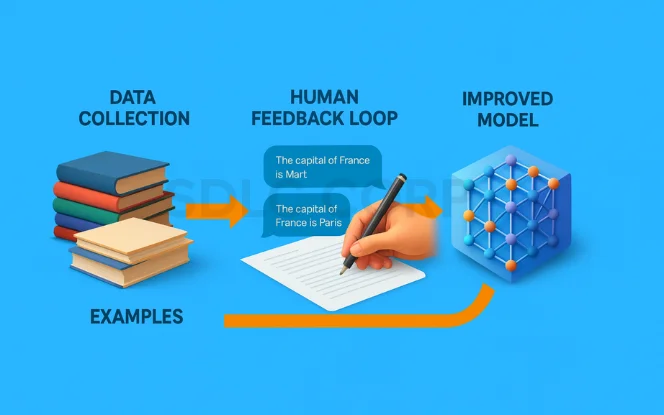
High-Level Workflow
Dataset Collection
Gather a diverse set of instruction–output pairs.
These examples demonstrate how the model should respond to different types of user inputs.
Supervised Instruction Tuning (SFT)
Train the model on collected data using supervised learning techniques.
Helps the model map human-written instructions to accurate and coherent responses.
Human Feedback Integration (RLHF)
After initial training, apply Reinforcement Learning from Human Feedback (RLHF) to further refine the model’s behavior.
Human evaluators rank model outputs, guiding the model toward safer, more helpful, and aligned responses.
Data Collection Examples
Crowdsourced Instructions
Real human-written instructions collected from users or annotators.
Synthetic Instructions (Self-Instruct)
Instructions generated by the model itself to expand training data without human labor.
Public Datasets
Includes well-known open-source datasets like:
- FLAN – A diverse set of instruction-following tasks.
- Alpaca – A dataset built from GPT-generated instructions.
- Zephyr – Recent datasets fine-tuned for alignment and safety.
Human Feedback Loop
After supervised training, human reviewers evaluate the quality, safety, and helpfulness of model responses.
Responses are ranked, and the model is updated accordingly using RLHF.
This feedback loop greatly improves the model’s ability to align with real-world human expectations.
Learn more : Large Language Models
3. Key Instruction Tuning Methods
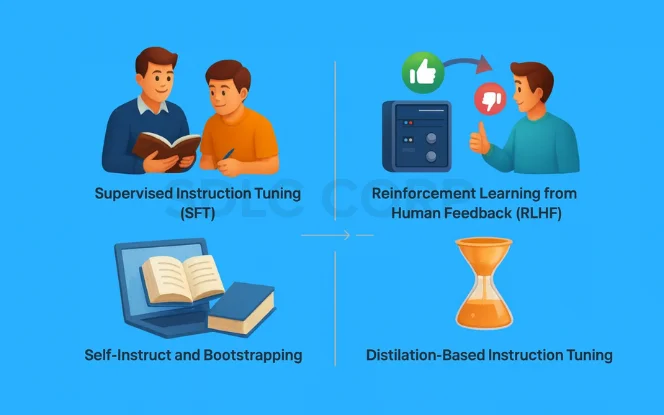
Instruction tuning is implemented using a variety of methods, each with its strengths and ideal use cases. Below are the four primary approaches:
Supervised Instruction Tuning (SFT)
Key Characteristics of Instruction Tuning
Trains models on labeled datasets with instruction–response pairs.
Helps models learn to follow a wide range of instructions directly and accurately.
Improves task generalization when exposed to diverse instruction sets.
Commonly Used Datasets
Natural Instructions – Human-annotated tasks collected across multiple domains.
Self-Instruct – Synthetic but diverse instructions automatically generated by models.
Dolly – Instruction-tuned dataset built from open-source prompts.
Reinforcement Learning from Human Feedback (RLHF)
Uses human rankings to train a reward model that evaluates response quality.
Applies policy optimization algorithms (e.g., PPO) to adjust the model based on feedback.
Enhances helpfulness, safety, and alignment beyond what supervised tuning alone can offer.
Notable Examples:
InstructGPT – Fine-tuned using RLHF to follow user prompts more reliably.
ChatGPT – Built using RLHF to improve conversational flow and safety.
Self-Instruct and Bootstrapping
A technique where a base model generates its own instructions and responses.
These synthetic examples are then used to fine-tune or retrain the same model.
Significantly reduces reliance on manual data labeling.
Benefits:
Scalable and cost-effective.
Useful for extending instruction-following capabilities with minimal human input.
Distillation-Based Instruction Tuning
Employs a teacher-student framework where a smaller model learns from a larger, instruction-tuned model.
The student model mimics the behavior of the teacher, gaining efficiency and speed.
Ideal for deploying AI on devices with limited compute resources.
Use Cases:
Compressing LLMs like GPT-3 into smaller models for mobile, embedded, or edge applications.
4. Datasets for Instruction Tuning
The effectiveness of instruction tuning heavily depends on the quality, diversity, and structure of the training datasets. Well-designed datasets help models generalize across a wide range of tasks and instructions.
Key Datasets
Natural Instructions
Curated, human-written task instructions covering multiple domains.
Includes clear input-output pairs and task definitions.
Great for training models to follow complex or nuanced instructions.
Super-NaturalInstructions
A scaled-up and extended version of the original Natural Instructions dataset.
Includes thousands of tasks with richer annotation and more diverse examples.
FLAN Collection
Developed by Google, the FLAN dataset combines a variety of task-based instructions from multiple sources.
Encourages strong zero-shot and few-shot performance across domains.
OpenAssistant Dataset
A large set of community-generated conversations and instructions.
Focused on dialogue-based instruction-following, useful for training assistants and chatbots.
Promotes openness and transparency in model training.
Best Practice for Dataset Design
Ensure diversity of tasks: Include instructions from various domains (e.g., math, writing, science, coding).
Use clear, well-formulated instructions: Ambiguity in training data leads to inconsistent outputs.
Balance human-written and synthetic data: Combining both improves scale and quality.
Emphasize instruction-response clarity: Each pair should be unambiguous and purposeful.
5. Applications of Instruction Tuning
Instruction tuning significantly enhances the ability of AI systems to understand and execute human commands across a variety of real-world applications.
Explore more : Agentic AI Fundamentals
Conversational Agents
Powers AI assistants like ChatGPT, Claude, and OpenAssistant.
Enables models to understand nuanced queries, follow conversational flow, and provide accurate, context-aware responses.
Improves coherence, tone adaptation, and multi-turn dialogue handling.
Task-Specific Assistants
Used in legal, medical, financial, and other domain-specific AI systems.
Enhances the reliability, accuracy, and control of specialized models.
Example: Legal document analysis tools or AI triage systems in healthcare.
Code Generation Tools
Models like Codex, Code LLaMA, and StarCoder are instruction-tuned to translate natural-language prompts into executable code.
Supports developers with code completion, bug fixing, and documentation generation.
Educational AI Tutors
Instruction tuning enables AI to adapt explanations, generate practice problems, and provide feedback tailored to a student’s level.
Facilitates personalized learning experiences across subjects.
Enterprise Productivity Tools
Enhances tools for document summarization, email drafting, knowledge search, and more.
Makes AI systems more intuitive and task-aware, improving efficiency for enterprise users.
6. Benefits of Instruction Tuning
Instruction tuning delivers several transformative advantages that significantly improve the practicality, reliability, and alignment of AI systems with real-world human needs. These benefits directly impact the model’s usability across domains such as healthcare, education, legal tech, and enterprise productivity.
Improved Alignment
Understanding Human Intent:
Instruction tuning helps models better grasp the intent behind a user’s input, not just the surface-level language. This is essential for nuanced tasks such as providing legal advice, writing emotionally aware content, or summarizing complex reports.
Contextual Awareness:
Tuning enables models to generate responses that are contextually appropriate and tailored to the prompt. This reduces misunderstandings and ensures outputs match the user’s expectations more closely.
On-Topic Responses:
Models learn to remain focused and relevant to the instruction given, rather than drifting into off-topic or overly generic answers.
Controllability
Predictable Behavior:
Instruction-tuned models are more consistent in their responses, making them easier to manage and integrate into larger systems (like chatbots, copilots, or enterprise workflows).
Safe Outputs:
Enhanced controllability helps reduce the risk of harmful, biased, or unethical content. This is particularly important in sectors where compliance, ethics, or legal boundaries are non-negotiable.
Behavioral Consistency Across Domains:
Whether the instruction comes from a teacher, doctor, or customer, the model responds reliably, adapting its tone and style accordingly.
Better Generalization
Cross-Task Flexibility:
Unlike traditional fine-tuning (which is task-specific), instruction tuning allows models to perform well across unseen tasks, simply by understanding the nature of the instruction.
Supports Zero-Shot and Few-Shot Learning:
Instruction-tuned models can often complete tasks they’ve never seen during training, given only a clear instruction or a few examples without retraining.
Domain Adaptability:
This generalization ability is valuable for building multi-purpose AI systems that can switch contexts (e.g., from writing code to drafting policy documents) seamlessly.
Reduced Hallucination
Improved Factual Accuracy:
Instruction-tuned models are more likely to provide fact-based, concise, and grounded responses when asked for specific information.
Minimized Fabrication:
By learning how to respond within realistic parameters, these models reduce the likelihood of “hallucinating” or inventing false details an essential quality for applications in science, law, and medicine.
Supports Model Trustworthiness:
Users are less likely to encounter misleading or overly confident false statements, which is crucial for decision-making processes.
User Trust
Reliable Output Quality:
Consistent, relevant, and accurate responses build user confidence over time, especially when dealing with complex or sensitive tasks.
Human-Like Interaction:
As instruction tuning improves alignment and communication style, users experience more natural, fluid interactions making the AI feel more intuitive and user-friendly.
Enables Wider Adoption:
When users trust the system, they’re more likely to adopt it in high-stakes environments such as healthcare diagnostics, corporate decision-making, customer support, and legal research.
7. Challenges and Limitations

While instruction tuning has proven highly effective in aligning AI models with human intent, several challenges and limitations remain. These issues impact both the development and deployment of instruction-tuned models and must be considered for responsible and sustainable AI use.
Data Quality
Impact on Model Behavior:
The effectiveness of instruction tuning is highly dependent on the quality of the instruction-response pairs used for training. Poorly written, ambiguous, or inconsistent instructions can confuse the model and lead to unpredictable or irrelevant outputs.
Garbage In, Garbage Out:
If the training dataset includes vague or misleading tasks, the model will struggle to generalize accurately across real-world scenarios.
Need for Standardization:
Lack of standardized formats for instruction data can make integration and reuse difficult across projects or platforms.
Cost of Human Feedback
Expensive and Time-Intensive:
Collecting and ranking high-quality human feedback especially for reinforcement learning from human feedback (RLHF) requires expert annotators and substantial resources.
Scalability Issues:
As models scale in complexity, the volume of required feedback increases, making it challenging to maintain quality and coverage.
Dependence on Subjectivity:
Human feedback is inherently subjective, which can introduce inconsistencies and noise into the reward signal.
Ethical Risks
Bias in Instructions and Responses:
If training data or feedback reflects human biases consciously or unconsciously the model may learn and reinforce harmful stereotypes or unfair assumptions.
Amplification of Social Norms:
Without careful curation, instruction-tuned models can propagate cultural, political, or gender biases embedded in their data.
Misinformation and Misuse:
If not carefully monitored, tuned models may still generate convincing yet false information, especially in sensitive domains like healthcare or finance.
Continual Learning and Catastrophic Forgetting
Challenge of Model Updates:
Updating models with new data or tasks can sometimes cause them to forget previously learned behaviors or instructions. This is known as catastrophic forgetting.
Balancing Adaptability and Retention:
It’s difficult to ensure a model remains flexible and up-to-date while preserving the benefits of prior tuning.
Lack of True Continual Learning Mechanisms:
Most current instruction-tuned models operate in static training regimes and are not equipped to learn incrementally without retraining.
Know more : Text-to-Image Generation Tools
8. Best Practices and Future Trends
To ensure instruction tuning yields accurate, safe, and efficient results, developers and researchers must follow proven practices while keeping an eye on emerging trends that will shape the future of AI alignment.
Best Practices
Use Clear, Diverse, Domain-Specific Instructions
Instructions should be well-formulated, unambiguous, and cover a wide range of tasks and domains (e.g., healthcare, legal, creative writing, coding).
Diversity improves the model’s ability to generalize and reduces overfitting to narrow use cases.
Blend Human and Synthetic Data for Scale and Quality
Human-curated data ensures quality and nuance.
Synthetic data (e.g., from self-instruct methods) adds scalability at a low cost.
A hybrid dataset strategy balances quality, coverage, and cost-effectiveness.
Monitor Outputs for Bias and Hallucination
Regularly evaluate the model for ethical risks, bias, and factual correctness.
Implement automated tools and human review to catch problematic outputs before deployment.
Future Trends
Hybrid Instruction Tuning Approaches
Combines SFT (Supervised Instruction Tuning), RLHF (Reinforcement Learning from Human Feedback), and prompt engineering.
Provides finer control over outputs and stronger alignment with human intent.
Accelerates model adaptation to new domains and tasks.
Open-Source Democratization
Projects like OpenAssistant, Zephyr, and Dolly are lowering barriers to entry.
Promotes transparency, reproducibility, and open collaboration.
Expands access to instruction-tuned models for researchers and developers.
Smaller Models with Bigger Impact
Lightweight models (e.g., LLaMA, Mistral) can now compete with larger models.
Enables edge deployment and use in low-resource environments.
Delivers faster inference speeds, making AI more accessible and efficient.

Conclusion
Instruction tuning is transforming how large language models (LLMs) understand and respond to human input. By teaching models to follow natural instructions, we unlock AI that is not only more useful and accurate but also safer and more general-purpose.As the field continues to evolve, it presents exciting opportunities for researchers, developers, and businesses to build smarter, more aligned systems. For organizations looking to leverage this powerful technique, AI Development Services can provide the tools and expertise to create tailored, instruction-tuned solutions that meet real-world needs.
FAQs
What is instruction tuning in AI?
Instruction tuning is a training method where language models are taught to follow human-written instructions to generate helpful and aligned responses.
How is instruction tuning different from fine-tuning?
While fine-tuning adapts a model to specific tasks or domains, instruction tuning teaches it to follow general natural-language commands across tasks.
Which models use instruction tuning?
Popular models include InstructGPT, ChatGPT, FLAN-T5, Alpaca, Zephyr, and OpenAssistant.
What are the best datasets for instruction tuning?
Top datasets include Natural Instructions, Super-NaturalInstructions, FLAN Collection, and the OpenAssistant dataset.
Can small models benefit from instruction tuning?
Yes, even small models can achieve impressive results when trained using distilled or synthetic instruction datasets.