Introduction
Multimodal AI is transforming how machines understand the world by combining text, images, audio, video, and sensor data just like humans use multiple senses to interpret their environment. Unlike traditional AI that relies on a single input type, this approach enables more intelligent, context-aware interactions.
In 2025, cutting-edge models like GPT-4o, Google Gemini, and Meta’s CM3Leon are pushing boundaries in virtual assistants, autonomous vehicles, and more. Businesses are rapidly adopting this powerful tech, often through AI development services, to build smarter and more intuitive solutions.

1. What is Multimodal AI
Multimodal AI refers to artificial intelligence systems capable of interpreting, processing, and combining data from multiple input types such as text, images, audio, video, and sensor data. These systems emulate the way humans use multiple senses to understand their environment and make informed decisions. Unlike single-modality systems that specialize in just one form of input (such as text or image), multimodal AI fuses different types of data for a more comprehensive, human-like understanding.

| Concept | Description | Example |
|---|---|---|
| Multimodal AI | Combines multiple data types | Text + Image |
| Multitask AI | Handles different types of tasks | Translation + Summarization |
| Multisensory AI | Overlaps with multimodal but focuses on human-like sensory simulation | Robots using Touch + Sight |
Types of Inputs Handled by Multimodal AI
To truly understand environments and contexts, multimodal AI must integrate a variety of data inputs:
- Text: This includes natural language from chat messages, reports, and emails. Text helps models interpret commands, comprehend context, or extract information.
- Images: Visual inputs such as photographs, X-rays, scanned documents, or objects captured via cameras provide spatial and aesthetic context.
- Audio: Sound inputs from voice commands, recorded speech, environmental noise, or even tonal fluctuations help with intent detection, speech recognition, and sentiment analysis.
- Video: Moving visuals like surveillance feeds or live streams offer sequential understanding, useful in behavioral monitoring or multimedia analysis.
- Sensor Data: From wearables, IoT devices, or autonomous systems, sensor data (like GPS, temperature, or pressure) gives crucial physical or environmental information.
These data streams provide complementary views of a situation, enabling more nuanced insights and reducing the ambiguity present in single-modality interpretation.
2. Why Is Multimodal AI Gaining Momentum

Multimodal AI is growing because it enables more natural, human-like interactions by combining text, images, audio, and video, powered by advances in deep learning and computing.
Explosion of Multisource Data
We live in an age dominated by digital devices that continuously generate diverse types of data. Smartphones, smartwatches, security systems, and connected vehicles collectively contribute to a deluge of real-time information. Multimodal AI is a natural evolution that helps organizations make sense of this complex, multimodal data universe.
Pursuit of Human-Like Intelligence
Humans rarely rely on a single sense. We watch facial expressions, listen to tones, read between the lines, and interpret gestures. To make machines truly intelligent, they must mimic this multisensory approach. Multimodal AI is the stepping stone toward artificial general intelligence (AGI), giving machines situational awareness, empathy, and flexibility.
Advances in Foundational AI Models
Breakthroughs like GPT-4o, Gemini, and Claude have unlocked the potential to unify different modalities within a single architecture. These models process and reason over data in various formats whether reading a document, viewing an image, or responding to speech. This convergence significantly enhances the quality and adaptability of AI applications.
Edge Computing & 5G Integration
The growth of edge computing and the rollout of 5G are pivotal. Multimodal systems can now run on smartphones, AR headsets, or drones, offering real-time decision-making capabilities in latency-sensitive applications like navigation, industrial automation, and telemedicine.
3. How Multimodal AI Works
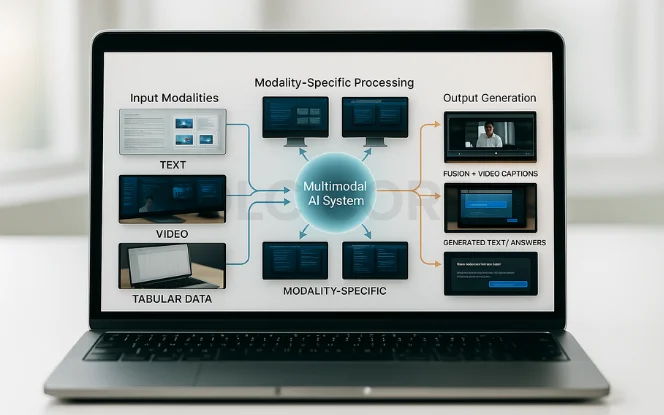
Understanding how multimodal AI functions requires a look into the interplay between its components. At the heart of these systems lies a design philosophy centered around data fusion, cross-modal alignment, and deep learning architectures.
Fusion of Multiple Data Types
Fusion is the process of integrating information from different modalities to create a unified representation.
Depending on the system’s purpose, this fusion can occur at different levels:
- Early Fusion: Combines raw or low-level data features before deep processing (e.g., image pixels + text tokens).
- Late Fusion: Independently processes each modality and merges their outputs or predictions.
- Hybrid Fusion: Mixes both approaches to balance early insights with refined decision-making.
Each approach has its strengths:
- Early fusion allows for tight integration and context sharing from the beginning.
- Late fusion supports modularity and flexibility, especially when certain modalities are optional or noisy.
- Hybrid fusion leverages the best of both worlds, often used in complex applications like autonomous systems.
Role of Foundation Models
Large-scale foundation models like GPT-4o and Gemini act as the “brain” of multimodal AI systems. They are trained on vast, diverse datasets containing images, text, videos, and sounds, allowing them to form semantic links across modalities.
These models understand prompts like:
- “Describe this image” (input: image → output: text)
- “Generate music for this video” (input: video → output: audio)
- “Summarize this meeting” (input: audio + transcript → output: text)
What makes them powerful is their ability to generalize and adapt, often using a single model for dozens of tasks.
Data Alignment & Cross-Modal Attention
A critical challenge in multimodal AI is aligning the right parts of one modality with another. For instance:
- A spoken sentence must match the correct visual frame in a video
- An image region must be associated with the appropriate description
- A temperature spike from a sensor must correspond with a visual anomaly on camera
To solve this, models use cross-attention mechanisms neural network layers that learn how elements across modalities relate. These mechanisms enable dynamic focus, allowing the model to attend to the most relevant features regardless of the input type.
Training such models involves:
- Multimodal corpora: Huge datasets that combine images with captions, videos with dialogues, sounds with transcripts, etc.
- Contrastive learning: A method where the model learns to associate matching pairs (e.g., a cat picture and the word “cat”) while distinguishing them from mismatched ones.
- Self-supervised learning: Where the model predicts missing data (e.g., filling in a masked word or image region), improving its understanding of the data structure across modalities.
4. Core Technologies Behind Multimodal AI
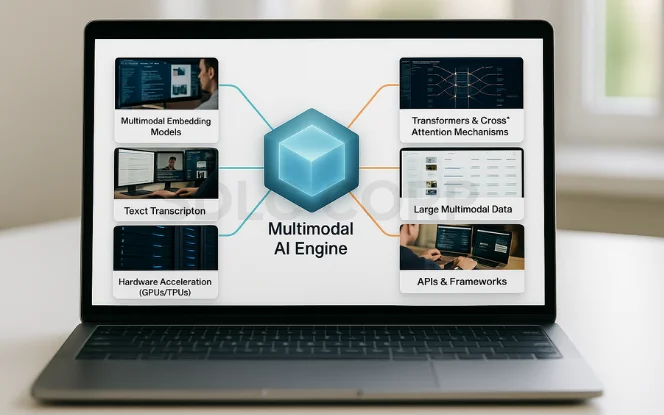
Multimodal AI uses transformers, computer vision, and NLP with fusion techniques to process and integrate text, images, audio, and video into coherent, context-aware outputs.
Transformers & Neural Architectures
Transformers are the backbone of today’s AI models. Their attention mechanisms allow them to handle variable-length sequences, and recent variants adapt them to vision (ViT), audio (Audio Transformer), and multimodal fusion.
Vision-Language Models (VLMs)
CLIP (OpenAI)
CLIP jointly trains vision and text representations. It enables models to understand phrases like “a red apple” and recognize the corresponding image—even without task-specific training.
Flamingo (DeepMind)
Flamingo is tailored for few-shot learning in visual question answering and captioning. It generates coherent textual responses from images, useful in education and accessibility tools.
Audio-Language Models
Whisper (OpenAI)
Whisper is a robust speech recognition model. It supports multiple languages, accents, and noise levels. Ideal for accessibility, translation, and voice-enabled AI.
AudioLM (Google)
This model specializes in audio generation and speech continuation, allowing systems to complete a spoken phrase or generate background sound for scenes.
Sensor Fusion
Sensor data (from accelerometers, GPS, LIDAR, etc.) is integrated in robotics and autonomous systems. Sensor fusion algorithms combine physical feedback to build situational awareness and real-time decision making.
5. Applications of Multimodal AI
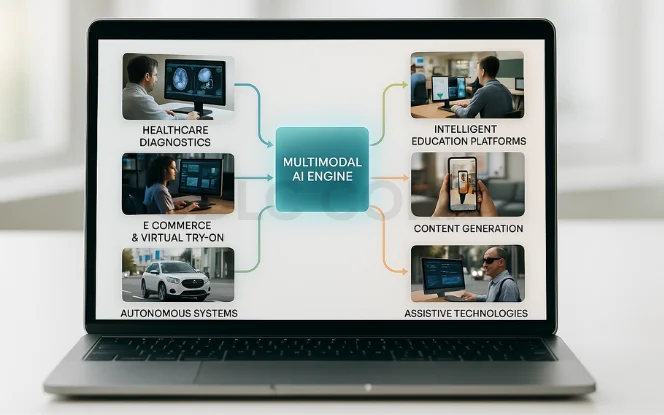
Multimodal AI enhances assistants, healthcare, autonomous vehicles, content creation, and security by integrating data from text, images, audio, and sensors.
Healthcare
- Radiology + EHR: AI that reads CT scans and patient history to assist in diagnostics.
- Multimodal Chatbots: Combine text and voice to support patients in understanding medical advice.
- Surgical Robotics: AI monitors video feed, surgical instrument pressure, and biometric signals to guide procedures.
Autonomous Vehicles
- Environment Awareness: Use visual sensors, GPS, radar, and sound to detect obstacles, road conditions, and emergency signals.
- Human Interaction: Interpret hand gestures or verbal instructions from pedestrians and passengers.
Customer Service
- Emotional Intelligence: Detect customer frustration via tone analysis.
- Image Interpretation: Analyze photos or screenshots shared by users to resolve issues.
- Omnichannel Support: Seamlessly handle queries across voice, text, and visuals.
Creative Content Generation
- Text-to-Video: Convert script into animated sequences or explainer videos.
- Interactive Storytelling: Dynamic stories that adapt based on user’s spoken input or gaze direction.
- AI-Generated Media: Produce music, art, and voiceovers from simple textual prompts.
6. Benefits of Multimodal AI

Natural Communication – Interprets language, gestures, images, and tone together for more human-like interactions.
Deeper Contextualization – Improves accuracy by cross-referencing multiple data sources.
Accessibility – Empowers people with visual, auditory, or motor impairments to interact seamlessly with technology.
Personalization – Adapts to individual preferences by learning from speech tone, visual cues, and behavior patterns.
Automation & Efficiency – Accelerates complex decision-making in industries such as logistics, healthcare, and finance.
Cost Savings – Reduces labor needs and operational expenses through intelligent automation.
Productivity Boosts – Streamlines workflows and enables faster task completion across teams.
Customer Satisfaction – Delivers more relevant, responsive, and engaging experiences that foster loyalty.
7. Challenges and Limitations
- Data Annotation Complexity: High-quality multimodal datasets are expensive and hard to produce.
- Hardware Demands: Processing rich inputs like high-res video or 3D LIDAR data requires powerful GPUs.
- Bias Propagation: If one data stream is biased (e.g., images or text), it can affect the output across all modalities.
- Interpretability: It’s hard to understand which modality influenced a specific decision.
- Latency: Integrating inputs in real time, especially on edge devices, can cause delay.
8. The Future of Multimodal AI
- AGI Potential: Combining modalities is a critical step toward Artificial General Intelligence.
- Immersive XR: Powering spatial computing experiences with vision, voice, and gesture recognition.
- Smart Robotics: Robots that see, hear, and feel can assist in eldercare, factories, and search & rescue.
- Market Growth: Multimodal AI industry projected to cross $50 billion by 2030.
- Open-Source Democratization: More accessible toolkits and datasets will allow startups and researchers to innovate rapidly.
What’s Next in 2026–2030:
Multimodal Search Engines – Unified search across text, images, and voice for precise results.
AI Companions with Persistent Memory – Long-term contextual understanding for personalized assistance.
Multilingual + Multimodal Models – Seamless integration of languages with text, visuals, and audio.
9. Top Multimodal AI Tools & Platforms

ChatGPT said:
Leading multimodal AI platforms include OpenAI GPT-4o, Google Gemini, Microsoft Azure AI, Anthropic Claude, and Meta ImageBind, enabling integrated processing of text, images, audio, and more.
| Tool | Highlights |
|---|---|
| GPT-4o (OpenAI) | Real-time, multimodal interactions across text, image, and voice |
| Gemini (Google) | High-level reasoning and cross-modal logic in chat, code, and vision tasks |
| CM3Leon (Meta) | Bidirectional generation of text + images; supports editing and inpainting |
| Hugging Face | Multimodal transformer models, datasets, and collaborative community tools |
| NVIDIA Omniverse AI | Industrial use cases—sensor + simulation + vision for factories and robotics |
10. Industry Use Cases of Multimodal AI
Multimodal AI is used in healthcare for combining scans and patient data, automotive for autonomous driving, retail for visual search and personalized recommendations, media for content creation, and security for enhanced surveillance and threat detection.
Education
- AI tutors understand speech, handwriting, and gestures.
- Personalized lesson plans based on spoken feedback and learning pace.
- Language learning with real-time pronunciation correction and lip reading.
Retail & E-commerce
- Visual and voice-enabled product search.
- AR-based fitting rooms that read body posture and provide recommendations.
- Shopping assistants that converse via voice and screen visuals simultaneously.
Entertainment
- Emotion-aware music creation.
- Games that respond to player expressions, tone, or movement.
- Content generation tools for social media: AI video, subtitles, and music from one prompt.
Cybersecurity
- AI that combines video surveillance, sound alerts, and email monitoring.
- Detects suspicious activity by correlating textual, audio, and visual data
- Enhanced anomaly detection by fusing logs, network behavior, and physical surveillance data.
11. Ethical Considerations in Multimodal AI
As multimodal AI systems grow in capability and pervasiveness, they also introduce a range of ethical concerns that must be addressed. These systems do not operate in a vacuum they observe, interpret, and sometimes act upon data collected from real people in real environments. This opens up critical debates about privacy, fairness, consent, and accountability.
Data Privacy and Surveillance
One of the most pressing ethical challenges is safeguarding personal privacy. Multimodal systems often rely on data captured from cameras, microphones, GPS devices, and other sensors. While this enables powerful applications from security to customer service it also raises questions about who is watching, what is being recorded, and how that information is being used.
Visual data from public cameras might inadvertently capture individuals without their knowledge.
Audio recordings, such as smart speaker inputs, can include private or sensitive conversations.
Sensor data, like biometric or location inputs, can be used to infer personal habits and behaviors.
This real-time, often continuous data collection pushes the boundary between utility and surveillance. To ensure ethical deployment, organizations must implement clear policies on data minimization, anonymization, and encryption, and should offer users transparent control over their data.
Bias in Image and Text Datasets
Multimodal AI models are trained on large datasets that often contain embedded societal biases. If these biases are not addressed, they can lead to harmful or discriminatory outcomes.
Image datasets might overrepresent certain demographics while underrepresenting others, leading to skewed recognition performance across racial or gender lines.
Textual data can contain stereotypes, toxic language, or cultural assumptions that models might learn and reproduce.
Cross-modal interactions (e.g., image + caption generation) can amplify these issues, leading to offensive or inaccurate outputs.
Bias in training data can be hard to detect and even harder to remove once a model is trained. Ethical AI development must prioritize dataset auditing, fairness metrics, and inclusivity testing across all modalities.
Consent and Data Ownership
Many multimodal systems operate in environments where individuals may not be fully aware that their data is being captured. This is especially problematic in public settings or when AI is embedded in consumer products.
Do users know their voice is being recorded?
Did someone consent to being filmed by a store’s AI analytics camera?
Who owns the data captured by smart home devices: the user or the provider?
Ethical multimodal AI requires clear and accessible mechanisms for obtaining consent, offering opt-out choices, and clarifying data ownership. Regulatory frameworks like GDPR and CCPA are beginning to set standards, but developers and businesses must go beyond compliance to build trust.

Conclusion
Multimodal AI is no longer a futuristic concept it’s a present-day reality reshaping how machines perceive and interact with the world. By integrating various data types, it enables smarter, more human-like experiences across industries. As models like GPT-4o, Gemini, and CM3Leon continue to advance, the possibilities for innovation are endless. Ready to harness the power of multimodal AI in your business? Explore our AI consulting services to get started with cutting-edge, custom-built solutions.
FAQs
What is multimodal AI?
Multimodal AI is an artificial intelligence system that processes and understands multiple forms of input such as text, images, audio, and video.
How is multimodal AI different from traditional AI?
Traditional AI models are usually unimodal (e.g., only text or only vision), while multimodal AI combines multiple data types for more context-rich understanding.
What are some examples of multimodal AI?
Examples include:
- GPT-4o (handles text, audio, image)
- Chatbots that analyze user voice and images
- Autonomous vehicles processing LIDAR + camera + GPS
Is GPT-4o a multimodal model?
Yes, GPT-4o is a true multimodal foundation model that handles text, images, and voice inputs natively.
Can multimodal AI be used in small businesses?
Absolutely. Tools like GPT-4o API and Hugging Face models make multimodal AI accessible to startups and SMEs with cloud-based solutions.