Introduction
The RAG Model (Retrieval-Augmented Generation Model) is reshaping artificial intelligence by merging two powerful capabilities: retrieval and generation. Unlike traditional large language models (LLMs) that rely only on pre-trained datasets, the RAG Model can fetch information from external sources in real time. This means it delivers answers that are not only more accurate but also up to date and contextually reliable. From healthcare AI solutions and finance to education and customer service, the RAG Model is driving the next wave of AI innovation by making responses grounded, trustworthy, and industry-ready. Ready to integrate AI into your business? Explore our AI Development Services.

1.Core Components of the RAG Model
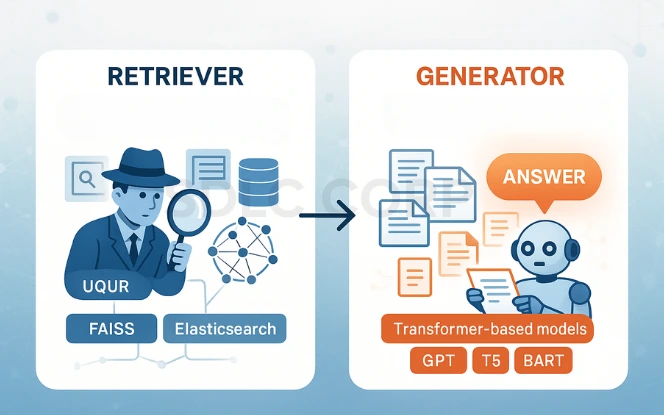
RAG consists of two primary modules, each playing a critical role in the generation process:
Retriever
Role: Acts like a digital researcher.
In other words, it retrieves relevant passages or documents from an external corpus or knowledge base.
Mechanism: Uses advanced search techniques like dense vector similarity. It matches user queries with documents based on semantic understanding rather than simple keyword matching.
Customization: For example, it can be fine-tuned to specific domains (e.g., legal, medical, academic).
Tools Used: FAISS, Elasticsearch, or custom neural retrieval models.
Generator
Role: Functions as the language expert or writer.
Function: Processes the retrieved documents to synthesize a coherent and context-rich answer.
Mechanism: Utilizes transformer-based models such as GPT, T5, or BART. It reads multiple documents and constructs a single narrative or answer.
Capabilities: Handles paraphrasing, summarizing, and integrating information. Moreover, it maintains fluency, coherence, and relevance in output.
Enhancements: Can be optimized for tone, format, and length.
2. How the RAG Model Works: Step-by-Step
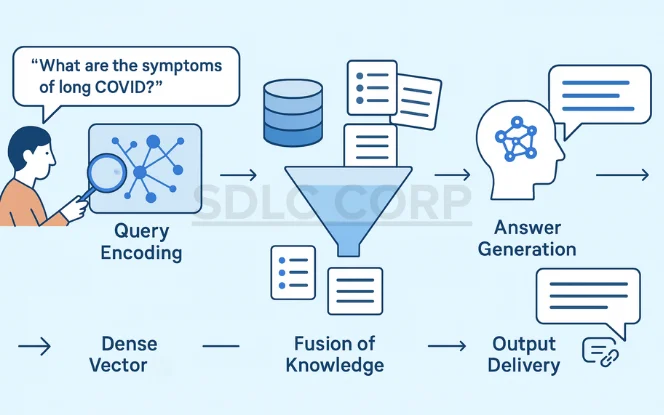
The RAG process involves a systematic pipeline that transforms raw queries into informed responses:
User Input: The process begins with a user submitting a query (e.g., “What are the symptoms of long COVID?”).
Query Encoding: The input is converted into a dense vector using an embedding model. This vector captures the semantic intent of the query.
Document Retrieval: The retriever searches a document index using the query vector. As a result, it returns the top-k most relevant documents based on similarity scores.
Fusion of Knowledge: Retrieved documents are selected, ranked, and pruned for relevance. These are then passed to the generator as additional context.
Answer Generation: Next, the generator synthesizes a response that integrates the retrieved content. Output is tailored, informative, and grounded in source material.
Output Delivery: The final answer is presented to the user. Often, it includes citations or links to source material.
3. Architecture Variants
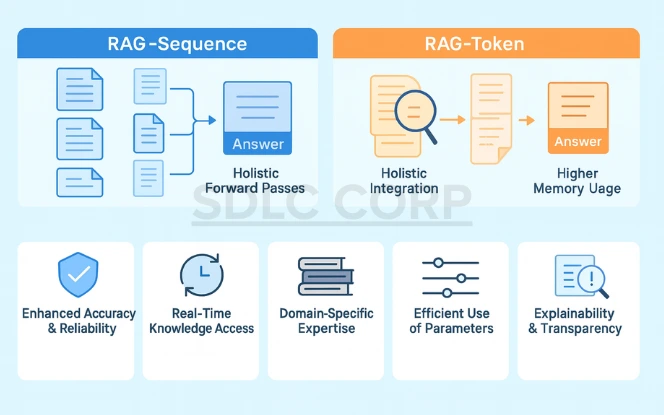
Different implementations of RAG offer trade-offs in performance, fluency, and computational efficiency:
RAG-Sequence
Mechanism: Processes each retrieved document independently. It generates multiple answer candidates, each based on a single document. The system then aggregates them (e.g., via marginalization or ranking) to produce the final answer.
Advantages: Encourages diversity in responses. Moreover, it is useful for comparing perspectives from different sources.
Limitations: Higher computational cost due to multiple forward passes. Consequently, it may generate inconsistent answers if sources conflict.
RAG-Token
Mechanism: Conditions each token generation on all retrieved documents simultaneously. This allows a more blended and holistic integration of information.
Advantages: Produces more coherent and unified responses. In addition, it is better at synthesizing complementary content.
Limitations: Requires more memory and compute resources. As a result, it may dilute conflicting information, reducing diversity of output.
4. Real-World Applications of the RAG Model
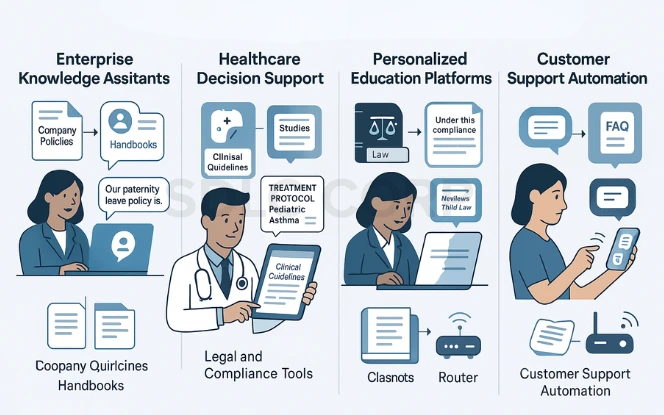
Enterprise Knowledge Assistants
Use Case: Streamlining access to internal organizational knowledge.
For example, an HR chatbot can answer, “What is the current paternity leave policy?” by pulling the latest document and summarizing it. As a result, employees save time and ensure consistency.
Healthcare Decision Support
Use Case: Assisting medical professionals in making informed clinical decisions.
For instance, a doctor could ask, “What’s the recommended treatment for pediatric asthma?” and receive a synthesized answer referencing guidelines. Consequently, this reduces the burden of manual research and helps prevent errors.
Legal and Compliance Tools
Use Case: Enhancing legal research and ensuring compliance adherence.
RAG can scan legal texts, regulations, and compliance manuals. Therefore, officers reduce the risk of oversight and save time on document analysis.
Personalized Education Platforms
Use Case: Delivering customized educational support.
For example, a student might ask, “Explain Newton’s Third Law,” and get a curriculum-aligned explanation. In addition, learners benefit from real-time tutoring tailored to their level.
Customer Support Automation
Use Case: Improving efficiency and satisfaction in customer service.
For instance, a customer could ask, “How do I reset my router?” and get an answer sourced from the product manual. Consequently, ticket volumes drop and response times improve.
5. Challenges and Limitations of RAG
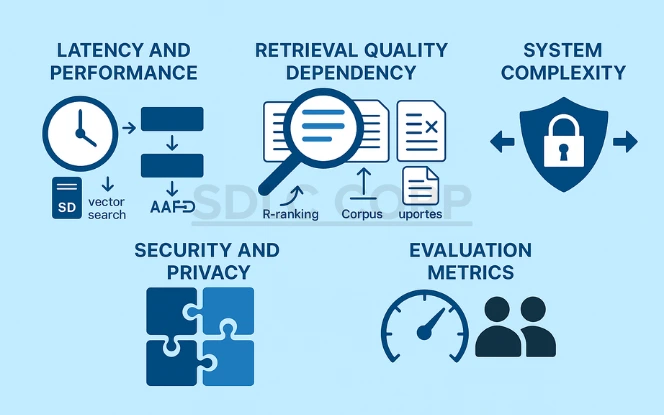
Latency and Performance
The RAG pipeline involves multiple steps, which add latency. Therefore, response times may be slower compared to purely generative models.
Retrieval Quality Dependency
The quality of the final response depends heavily on the retrieved documents. Poor retrieval leads to incoherent or incorrect answers. Consequently, even strong generators cannot fix flawed input.
System Complexity
Building and maintaining a RAG system requires coordinating multiple components. As a result, infrastructure costs rise and integration becomes more complex.
Security and Privacy
When accessing proprietary or sensitive data, improper retrieval practices can expose private information. Moreover, this may violate compliance regulations such as GDPR or HIPAA.
Evaluation Metrics
Traditional NLP metrics like BLEU or ROUGE don’t capture RAG’s quality fully. Therefore, human evaluation and task-specific metrics are necessary to measure effectiveness.
6. Future of the RAG Model in AI Development
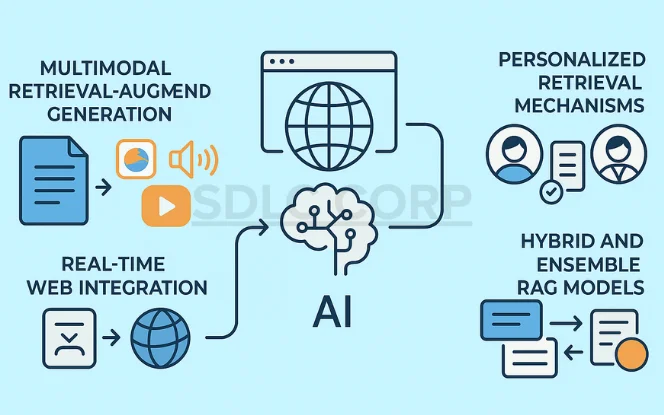
Multimodal Integration
The future of RAG lies in multimodal AI, where models don’t just retrieve and generate text but also combine images, audio, and video.
Context-rich reasoning: Imagine a RAG system retrieving a video clip, extracting frames, and combining them with textual data to answer complex questions.
Cross-domain learning: A multimodal RAG could analyze a medical scan (image), patient notes (text), and doctor’s voice recordings (audio) to provide comprehensive diagnostic support.
Personalization: In customer-facing applications, it could generate responses that adapt to user sentiment (from audio tone analysis) or preferences (from image/video cues).
Read More : Multimodal AI Technologies
Expansion into Regulated Industries
RAG adoption will accelerate in industries where accuracy, compliance, and trust are non-negotiable.
Healthcare: It can surface verified medical guidelines in real time while allowing clinicians to interact conversationally, reducing the risk of hallucinations.
Fintech: By pulling regulatory documents, financial data, and market trends, RAG can support investment analysis, fraud detection, and risk assessment while ensuring compliance.
Government: For policy and legal frameworks, RAG ensures officials have traceable, evidence-backed outputs, enhancing transparency in decision-making.
Enterprise SaaS and Knowledge Systems
Enterprises are drowning in unstructured data RAG is becoming the bridge between scattered information and actionable insights.
Smarter Knowledge Access: Employees won’t need to sift through wikis, tickets, or reports. RAG can retrieve contextually relevant information across silos in real time.
Decision Support: SaaS platforms will embed RAG to provide instant, explainable insights, improving productivity across sales, customer service, and operations.
Dynamic Adaptability: Unlike static AI models, RAG can update its retrieval layer instantly, keeping enterprises aligned with evolving knowledge bases.
Transparency, Governance, and Compliance
One of the biggest challenges in AI adoption is trust. RAG has a natural advantage here.
Source-grounded outputs: By citing sources, RAG reduces hallucinations and increases explainability.
Governance frameworks: Future RAG systems will log retrievals, allowing auditors to track how and why a certain output was generated.
Bias mitigation: Retrieval layers can be tuned to ensure fairness and reduce exposure to toxic or biased content, critical in legal, medical, and financial applications.
Competitive Business Edge
For businesses, adopting RAG is not just about better answers, but about strategic advantage:
Accuracy & Reliability: Firms can make faster, data-backed decisions, improving outcomes and reducing risks.
Cost Efficiency: Since RAG reduces hallucinations, it lowers the need for extensive human verification of AI outputs.
Customer Trust: By offering explainable AI interactions, companies will differentiate themselves in markets where customers demand accountability.
Scalability: Businesses can scale AI systems without retraining entire models, simply by updating or expanding their retrieval databases.
Latency and Performance
The RAG pipeline involves multiple processing steps, which can add latency. As a result, response times may be slower compared to purely generative models.
Retrieval Quality Dependency
The accuracy of responses depends heavily on the quality of retrieved documents. Poor retrieval can lead to incoherent or incorrect outputs. Even strong generators cannot compensate for flawed input.
System Complexity
Building and maintaining a RAG system requires coordination across multiple components. This increases infrastructure costs and makes integration more complex.
Security and Privacy
When accessing proprietary or sensitive data, improper retrieval practices may expose private information. Such risks can also violate compliance standards like GDPR or HIPAA.
Evaluation Metrics
Traditional NLP metrics such as BLEU or ROUGE do not fully capture the quality of RAG outputs. Human evaluation and task-specific metrics are often necessary to measure effectiveness.
Conclusion
Retrieval-Augmented Generation (RAG) is a leap toward making AI not just smarter, but contextually aware. By combining real-time retrieval with language generation, RAG turns static models into dynamic knowledge engines. Moreover, its future lies in API integration, multimodal retrieval, personalization, and privacy-focused inference. Therefore, as demand for accurate, context-rich AI grows, RAG will become central to industries like healthcare, finance, and education. Explore our AI Development Services to tap into the power of intelligent retrieval.
FAQs
What is Retrieval-Augmented Generation?
Retrieval-Augmented Generation (RAG) is a hybrid AI framework that combines a document retriever with a text generator to produce accurate, contextually rich answers based on external knowledge.
How does RAG differ from traditional AI models?
Traditional models like GPT are trained once and then used as-is. They rely on what they’ve seen during training. RAG, on the other hand, can dynamically fetch information from external sources, making it more adaptive and up-to-date.
What are the main applications of RAG?
RAG is used in:
- Knowledge management systems
- AI chatbots and assistants
- Healthcare diagnostics tools
- Legal research platforms
- Educational tutoring engines
- Enterprise search tools
What are the challenges associated with implementing RAG?
Key challenges include:
- System latency due to multiple processing steps
- Ensuring retriever fetches high-quality documents
- Complex infrastructure requirements
- Privacy concerns when using sensitive datasets
- Difficulty in evaluation and benchmarking
How can businesses benefit from using RAG?
Businesses using RAG can:
- Provide real-time, context-aware customer support
- Enable smarter enterprise search
- Reduce training data needs by leveraging external corpora
- Create AI assistants that are domain-specific and highly accurate
- Increase productivity by automating complex knowledge work