
Introduction
Text-to-Speech AI systems are revolutionizing how we consume content. Imagine reading your favorite novel not with your eyes, but through a voice so lifelike it feels as if the narrator is in the room with you.
Now imagine that voice isn’t human. It’s artificial intelligence. This is the transformative power of Text-to-Speech (TTS) AI systems, a technology once confined to robotic, monotone outputs and now capable of generating dynamic, emotional, and human-like speech.

1. What Is a Text-to-Speech (TTS) AI System?
A Text-to-Speech AI system is software that converts written text into spoken words using synthetic voices. While earlier versions of TTS systems sounded robotic, today’s models generate voices so human-like that they often go unnoticed in everyday use. They interpret punctuation, context, and even emotional tone to deliver speech that feels organic.
Unlike simple screen readers or pre-recorded voice messages, modern TTS platforms leverage machine learning to dynamically create speech outputs that mimic human nuances, accents, and intent. This is especially significant in domains like education, healthcare, and entertainment, where clarity and empathy are essential.
Related Read: Curious about converting visuals into written content instead? Here’s what are 3 easy methods for turning an image into text.
2.The Evolution of TTS: From Robotic to Real
1. Rule-Based Systems: The First Step
The initial TTS systems were rule-based. These systems used hand-coded linguistic rules to convert text into phonemes (basic sound units) and generate speech. However, they were rigid, monotone, and lacked intonation making them difficult to listen to for extended periods.
adoption.
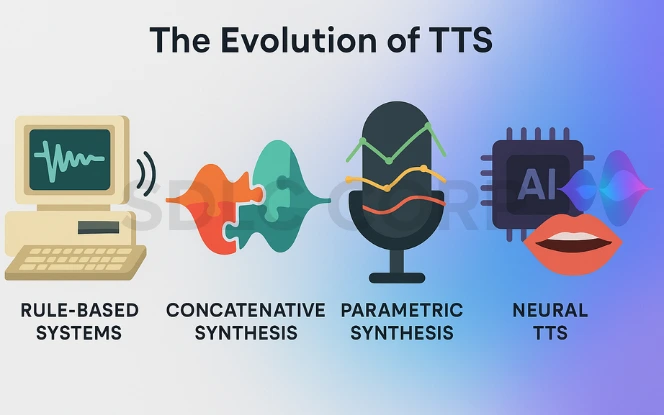
2. Concatenative Synthesis: Stitching Real Speech
Next came concatenative synthesis, which pieced together pre-recorded human speech fragments. This technique significantly improved clarity but was still limited. For one, it couldn’t handle spontaneous or uncommon words. It also struggled to modify emotion or inflection effectively.
3. Parametric Synthesis: Enter Machine Learning
Later, parametric synthesis introduced statistical modeling. These models generated sound using parameters like pitch, duration, and amplitude, allowing more variability than concatenative methods. Still, the results weren’t convincing enough for mainstream applications.
4. Neural TTS: The Breakthrough Era
The introduction of deep learning completely reshaped the landscape. Neural networks particularly those using attention mechanisms enabled TTS systems to analyze entire sentences, adjust prosody, and produce highly expressive and context-aware speech. Tools like Google’s Tacotron and DeepMind’s WaveNet began delivering near-human results, paving the way for widespread adoption.
Related Read:
Curious about converting visuals into written content instead?
Here are 3 easy methods for turning an image into text.
5. Advisory and System Design Considerations
TTS systems must address challenges related to voice quality, bias, and appropriate usage. Advisory input helps define system boundaries, data usage policies, and evaluation metrics. An AI consulting company may support organizations in designing responsible and context-appropriate TTS solutions.
3. How Do TTS Systems Work?
At first glance, the process may seem simple: input text and get audio. However, under the hood, it involves several complex layers.
listener.
Step 1: Text Preprocessing
TTS systems begin by cleaning and analyzing the input text. This step includes punctuation normalization, number expansion (e.g., “25” becomes “twenty-five”), and abbreviation handling.
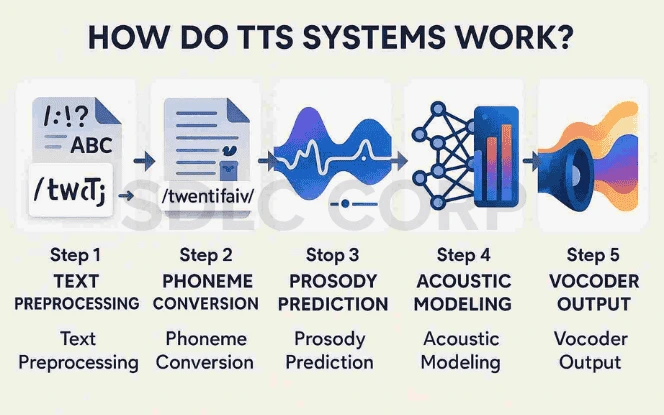
Step 2: Phoneme Conversion
The cleaned text is then transformed into phonemes. This ensures proper pronunciation. Language-specific rules or lexicons are used to determine correct phonetic representations.
Step 3: Prosody Prediction
Prosody involves pitch, rhythm, stress, and timing. AI models determine how each sentence should sound. Should the voice rise at the end? Is there a pause? Should a word be emphasized? This step brings life to flat text.
Step 4: Acoustic Modeling
Using deep learning models like Tacotron 2 or FastSpeech, the system maps phonemes to a spectrogram—a visual representation of the sound’s frequency and intensity over time.
Step 5: Vocoder Output
A neural vocoder like WaveNet, HiFi-GAN, or Parallel WaveGAN converts the spectrogram into an actual audio waveform that can be played aloud. The result is a natural-sounding voice ready to engage the listener.
4.Major TTS Platforms and Tools
Several platforms lead the Text-to-Speech AI market today. Each one brings its own strengths, whether it’s natural-sounding voices, real-time synthesis, language diversity, or advanced customization. Furthermore, as the demand for voice-based experiences grows, these tools continue to evolve to meet increasingly complex needs.
Google Cloud Text-to-Speech
Google’s Text-to-Speech service supports WaveNet voices, which are well-known for their high fidelity and natural tone. Additionally, developers benefit from seamless integration with Android and other Google Cloud APIs. Because of this, businesses can quickly build responsive voice applications with multilingual support, pitch control, and speech rate adjustment.
Amazon Polly
Amazon Polly, part of AWS, is widely used for its real-time streaming capabilities and flexible voice styles. It offers dozens of high-quality voices across multiple languages and supports both standard and neural Text-to-Speech options. As a result, Polly is ideal for application
Microsoft Azure Speech
Microsoft’s Azure Cognitive Services include one of the most diverse voice libraries available. With over 400 voices in more than 110 languages and variants, it provides expressive styles such as cheerful, sad, angry, or conversational. Moreover, Azure allows users to create custom neural voices, making it an excellent option for brands seeking a unique vocal identity.
IBM Watson TTS
Watson Text-to-Speech by IBM supports a wide array of languages and voices, including options for emotional tones and inflection control. Since it’s cloud-based, Watson can scale easily to meet enterprise-grade demands. Additionally, it offers SSML (Speech Synthesis Markup Language) support, enabling precise control over pronunciation and tone.
Resemble AI
Resemble AI focuses on custom voice cloning. With just a few lines of recorded audio, users can generate an AI voice that sounds remarkably personal. Beyond cloning, the platform supports real-time speech generation, emotional control, and voice synthesis in multiple languages. Therefore, it’s a popular choice for interactive games, film production, and virtual assistants.
Descript’s Overdub
Descript’s Overdub is tailored for creators. It allows podcasters, YouTubers, and video editors to “type and talk”, using a cloned version of their own voice. Furthermore, it seamlessly integrates with Descript’s powerful audio editing platform. That way, creators can make changes to recordings without the need to re-record audio manually.
5. Real-World Applications of TTS
Text-to-Speech AI systems are no longer limited to niche functions. On the contrary, they now power a broad spectrum of real-world applications, impacting accessibility, entertainment, business operations, and more. As technology continues to evolve, their presence across industries is becoming increasingly common and impactful.
Accessibility and Inclusion
Perhaps most importantly, Text-to-Speech AI systems are a lifeline for individuals with visual impairments, reading disorders like dyslexia, or motor disabilities. Because they convert written content into spoken voice, they eliminate the barriers of traditional text-based communication. Furthermore, assistive devices that include Text-to-Speech functionality help users browse the web, read emails, and interact with applications—independently and efficiently.
Education
In educational environments, these systems are making learning more inclusive and dynamic. For instance, learners can listen to textbooks, practice pronunciation, or hear real-time feedback in multiple languages. Additionally, teachers can use Text-to-Speech tools to create voice-based quizzes, instructional materials, or multilingual lesson support—without relying on human narrators.

Voice Assistants
Voice-enabled AI assistants like Google Assistant, Siri, and Alexa rely heavily on Text-to-Speech to communicate. As these systems grow more sophisticated, they now use contextual cues to vary tone, emotion, and pacing. As a result, the interactions feel more personal and conversational. Moreover, users now expect this level of speech engagement from everything from smart thermostats to wearable devices.
Customer Support
Text-to-Speech AI is also transforming the customer support industry. Since TTS can synthesize speech in real time, companies use it to automate voice responses across help desks, IVRs, and virtual agents. Consequently, customers receive immediate responses without waiting for a live representative. Moreover, TTS can personalize greetings, provide account-specific information, and support multilingual users—all without compromising on voice quality or clarity.
Entertainment
The entertainment industry has begun to adopt Text-to-Speech AI for interactive storytelling, character voiceovers, and voice dubbing. While game developers use it to dynamically voice in-game characters and side dialogues, streaming platforms are exploring it for real-time subtitle narration and audio descriptions. Furthermore, independent creators can now produce high-quality voiceovers for animations, trailers, or short films—at a fraction of the cost.
Navigation and Automotive
In the automotive sector, TTS plays a critical role in improving safety and user experience. Navigation systems now use AI voices to guide drivers, update traffic alerts, or even issue emergency notifications. Because these voices are clear, responsive, and natural-sounding, drivers can rely on them for real-time information without distraction. Moreover, voice-controlled infotainment systems enhance convenience by allowing hands-free access to messages, media, and more.
6. Advantages of TTS Systems
As artificial intelligence continues to advance, the benefits of Text-to-Speech AI systems are becoming more pronounced and widespread. These systems are no longer optional tools they are becoming essential components of digital infrastructure. In this section, we’ll explore how Text-to-Speech AI is transforming the way individuals and businesses interact with content.
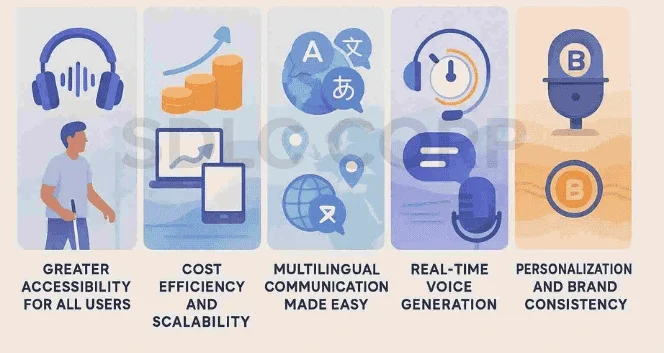
Greater Accessibility
Above all, Text-to-Speech AI promotes accessibility. By converting text into spoken language, it removes the barriers that traditional interfaces present for people with visual impairments, learning disabilities, or physical challenges. In fact, these systems enable users to consume content in environments where reading is inconvenient, such as while driving or exercising. Furthermore, screen readers and assistive apps powered by TTS have become vital for inclusive digital design.
Cost Efficiency
Hiring professional voice actors and booking studio time can be costly and time-consuming. Instead, businesses can now use Text-to-Speech AI to generate natural voiceovers on demand. Moreover, this approach scales easily whether you’re creating 100 or 10,000 pieces of content. As a result, companies save time, reduce overhead, and maintain voice consistency across multiple platforms.
Multilingual Communication
Many Text-to-Speech AI platforms support dozens of languages and dialects. Because of this, global businesses can deliver content to diverse audiences without hiring multilingual voice talent. Additionally, advanced systems can even replicate regional accents and local expressions. Therefore, organizations are now able to expand internationally while maintaining brand tone and linguistic accuracy.
Real-Time Generation
Another significant advantage is real-time speech synthesis. TTS engines can process and generate spoken responses in milliseconds, making them ideal for live interactions. For instance, chatbots, virtual assistants, and voice-driven applications all rely on this feature to engage users seamlessly. Not only does this enhance responsiveness, but it also improves customer satisfaction across digital channels.
Personalization
Text-to-Speech AI systems also offer deep customization. Users can choose a voice that aligns with their brand identity adjusting elements like pitch, tone, speaking speed, and emotion. Moreover, some platforms allow businesses to create custom neural voices that sound entirely unique. As a result, brands can establish consistent voice personas across customer service, training modules, marketing, and more.
7.Limitations and Challenges

While Text-to-Speech AI systems offer a range of powerful features, they are not without shortcomings. As the technology advances, developers and organizations must continue to address a variety of ethical, technical, and cultural challenges. Understanding these limitations is essential for deploying TTS solutions responsibly and effectively.
Voice Cloning Ethics
Although voice cloning allows for personalized experiences, it also introduces serious ethical risks. For example, synthetic voices can now closely replicate the speech of public figures or private individuals. Consequently, the potential for impersonation, misinformation, and fraud is greater than ever. In fact, deepfake audio scams are already emerging in financial and political spheres. Therefore, developers must implement safeguards such as consent protocols and watermarking to ensure ethical usage.
Emotional Nuance
Even though modern TTS engines can simulate emotion, they still struggle with subtleties such as sarcasm, irony, or regional humor. Without facial expressions or body language, these systems often miss the emotional context of a conversation. Furthermore, slight mismatches in tone can make AI voices seem unnatural or insincere. As a result, TTS is still not ideal for emotionally charged communication like therapy, coaching, or high-stakes negotiation.
Accent and Language Bias
Most commercially available Text-to-Speech systems are designed with English or other high-resource languages in mind. Because of this, users who speak minority languages or dialects often experience reduced accuracy and representation. In many cases, these voices are either unavailable or poorly trained. Moreover, even within a single language, accent bias may result in awkward pronunciation or a lack of cultural relatability. Therefore, inclusivity remains a critical area for improvement.
Monotony in Long-Form Use
Although neural TTS models have improved greatly, they can still sound monotonous during extended audio playback. Since dynamic prosody and varied emphasis are difficult to automate, listeners may grow fatigued when consuming audiobooks, courses, or lengthy reports via synthetic voices. To overcome this, some platforms now offer emotional modulation and scene-based delivery, but these features are not yet universal.
Cultural Misinterpretation
AI-generated speech may misinterpret culturally significant terms, names, or phrases. As a result, this can lead to unintentional offense or miscommunication. For instance, TTS systems might pronounce indigenous names incorrectly or misplace stress in culturally important idioms. Therefore, context-aware pronunciation models and culturally adaptive training data are essential for minimizing such errors.
8. The Future of TTS: What's Next?

Without a doubt, the Text-to-Speech AI landscape is evolving faster than ever before. As research accelerates and integration deepens across industries, we can expect the next generation of voice synthesis to be more intelligent, empathetic, and multilingual. Below are the most exciting directions this technology is heading each of which is poised to redefine how we interact with digital content.
Hyper-Personalization
Soon, users will gain far more control over how their synthetic voices sound. Rather than being limited to a fixed set of voices, individuals and brands alike will be able to customize tone, pitch, rhythm, pace, and mood. In fact, some platforms already offer dynamic sliders to adjust these parameters in real time. As a result, voice experiences will feel more human, adaptive, and emotionally relevant whether for e-learning, branding, or content creation.
Emotion-Aware Speech
As artificial intelligence becomes more contextually aware, emotion recognition is entering the world of Text-to-Speech. This means AI voices will be able to detect user sentiment and respond accordingly. For example, a virtual assistant might soften its tone when delivering bad news or sound excited when announcing a win. Furthermore, emotional modulation will allow customer service bots and health apps to sound more supportive and compassionate, improving user trust and retention.

Conclusion
Text-to-Speech AI systems are no longer a futuristic novelty; they are a fundamental part of the digital landscape. From accessibility and education to entertainment and enterprise, TTS is empowering people, businesses, and ideas through the simple yet profound act of giving voice to the written word. As AI continues to evolve, so too will the depth, nuance, and reach of TTS technologies.
Partnering with an experienced AI development company can accelerate the integration of TTS solutions into your platforms, products, or services ensuring you stay ahead in an increasingly voice-first world.
The question isn’t whether TTS will become a part of your life. It’s how soon, and in how many ways, you’ll be using it daily.
FAQ'S
Is TTS the same as speech recognition?
No, they are fundamentally different technologies. Text-to-Speech (TTS) converts written text into synthesized speech, allowing devices to “speak” to users. On the other hand, speech recognition does the reverse it listens to a user’s voice and converts it into text for processing or transcription. While both are part of broader voice AI systems, they serve opposite functions and are often integrated together in virtual assistants and voice-controlled applications.
Can I create a voice that sounds like me?
Yes, absolutely. Many modern TTS platforms now offer voice cloning or custom voice synthesis features. Tools like Resemble AI, Descript Overdub, Murf.ai, and Microsoft Neural Voice allow users to upload short voice samples (sometimes under 10 minutes) to train a custom model that mimics their speech patterns, tone, and accent. However, creating cloned voices may require user consent and, in many cases, licensing agreements, especially for commercial use.
Is TTS secure and ethical?
It depends on how the technology is used. Reputable TTS platforms implement strong security protocols to protect user data and voice samples. However, the ethical challenges arise with voice cloning—since synthetic voices can potentially be used for impersonation, misinformation, or fraud if misused. To ensure ethical use, always:
Obtain explicit consent from the original voice owner.
Use TTS solutions that adhere to GDPR, CCPA, or relevant data protection laws.
Choose providers with transparent usage policies and anti-abuse safeguards.
Which languages are supported?
Most leading TTS platforms like Google Cloud Text-to-Speech, Amazon Polly, Microsoft Azure Speech, and IBM Watson support over 70 to 100+ languages and dialects, including English, Spanish, Mandarin, Arabic, French, Hindi, and many more. However, low-resource or indigenous languages often receive limited support due to a lack of training data. That said, efforts are being made by research communities and nonprofits to expand multilingual inclusivity in AI.
Can TTS read websites or documents aloud?
Absolutely. TTS can read content from websites, PDFs, emails, and even apps. Tools like:
Read Aloud (Chrome extension)
Speech Central
Voice Dream Reader (iOS)
Narrator (Windows)
TalkBack (Android)
make it easy for users to consume text audibly. These features are especially helpful for people with visual impairments or reading disorders, and for multitaskers who prefer audio content while working or commuting.








