1. Introduction
Artificial Intelligence has moved beyond simple image recognition to generating human-like text. Now, Vision-Language Models (VLMs) take it further by combining visual data with natural language, enabling smarter, context-aware AI applications. For any AI development company, these models are a major step toward bridging the gap between human perception and machine intelligence.
From describing images to answering visual questions, VLMs are redefining machine learning. This blog explores what VLMs are, how they work, their key applications, and why they’re vital for the future of AI.

2. What Are Vision-Language Models?
Vision-Language Models (VLMs) are advanced AI systems that combine computer vision and natural language processing (NLP) into a unified framework. Unlike traditional models that only handle images or text independently, VLMs learn from both modalities simultaneously, allowing them to interpret visual content in context with language and generate meaningful text based on visual inputs. These models enable tasks like image captioning, visual question answering, and multimodal reasoning, making them crucial for the future of AI.

Popular Examples of VLMs:
- CLIP (OpenAI): Learns to connect images with their textual descriptions.
- Flamingo (DeepMind): Specializes in multimodal reasoning and dialogue.
- BLIP-2 & Kosmos-1: Designed for advanced multimodal understanding and generation.
- GPT-4V (OpenAI): Extends GPT-4 with powerful visual analysis capabilities.
Also read – Recurrent Neural Networks (RNNs)
3. How Do Vision-Language Models Work?
Vision-Language Models bridge the gap between pixels and words by leveraging transformer-based architectures and large-scale training on image-text pairs. They learn to extract visual features, align them with textual information, and generate contextually meaningful outputs.
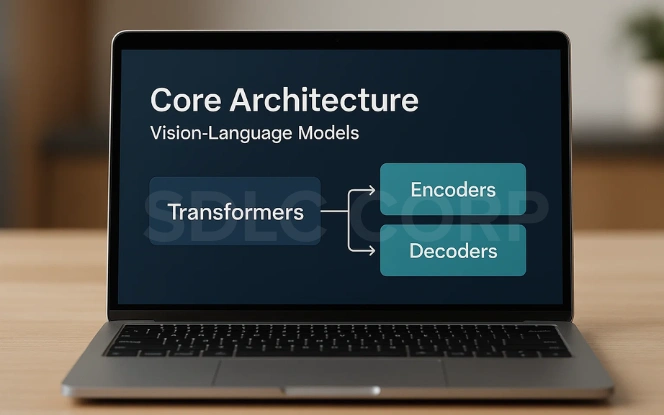
a) Core Architecture
- Transformers: The backbone for processing multimodal inputs.
- Encoders & Decoders: Extract and combine features from both text and images.
- Cross-Attention Layers: Allow the model to “focus” on relevant parts of an image while understanding text.
b) Training Techniques
- Contrastive Learning: Models like CLIP learn to link related images and texts by maximizing similarity between correct pairs and minimizing it for incorrect ones.
- Image-Text Pretraining: VLMs are trained on massive datasets of paired images and captions (e.g., LAION, COCO).
- Prompting & Fine-Tuning: Improves performance on specific tasks like Q&A or summarization.
4. Applications of Vision-Language Models
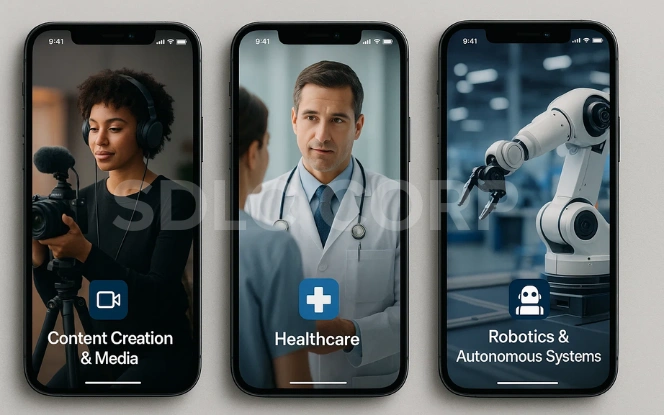
Vision-Language Models (VLMs) are revolutionizing how machines perceive and interact with the world, enabling breakthroughs across industries. By combining visual comprehension with language understanding, VLMs open the door to smarter automation, enhanced creativity, and better decision-making.
Key Applications:
Content Creation & Media:
- Automated Image Captioning: Generating accurate, context-aware captions for images on platforms like social media or e-commerce.
- Visual Storytelling & Creative Tools: Assisting creators in turning visual inputs into engaging narratives, scripts, or blogs.
- Video Summarization: Quickly condensing hours of video into concise highlights for journalism, education, and entertainment.
Healthcare:
- Medical Imaging & Diagnosis: Analyzing X-rays, MRIs, or CT scans alongside medical notes to aid in diagnosis.
- Clinical Documentation: Automating the creation of detailed medical reports by combining visual scans with patient data.
- Drug Discovery & Research: Using multimodal data to uncover patterns in medical images and research literature.
Search & Retrieval:
- Multimodal Search Engines: Enabling queries like “Find images of cars similar to this but in red color” or “Show me products like this.”
- E-commerce & Product Search: Improving visual product recommendations by linking images with descriptions and user intent.
- Knowledge Retrieval: Assisting researchers by matching visual data (charts, diagrams) with academic literature.
Robotics & Autonomous Systems:
- Enhanced Perception for Robots: Enabling robots to follow complex verbal instructions by understanding their visual environment.
- Autonomous Vehicles: Helping self-driving cars interpret street signs, pedestrians, and other contextual information.
- Industrial Automation: Allowing robots to identify and manipulate objects in warehouses or factories using multimodal understanding.
Accessibility:
- Assistance for the Visually Impaired: Describing surroundings, reading text from images, or guiding navigation in real time.
- Education & Inclusivity: Creating accessible learning materials for individuals with disabilities by merging images with descriptive audio/text content.
Security & Surveillance (Emerging Use):
- Analyzing video footage with contextual alerts (e.g., identifying suspicious activities with descriptive tagging).
- Enhancing law enforcement tools with combined visual evidence and textual context.
Also read – Convolutional Neural Networks (CNNs)
5. Top Vision-Language Models in 2025

The landscape of Vision-Language Models is evolving rapidly, with leading tech companies and research labs developing powerful multimodal AI systems that can understand and reason across images, text, and even other modalities.
Notable VLMs in 2025:
- OpenAI GPT-4V: An extension of GPT-4 with advanced visual understanding, capable of analyzing images, generating context-aware descriptions, and performing complex multimodal reasoning tasks.
- Google Gemini: A next-generation multimodal AI system that seamlessly integrates vision, language, and reasoning capabilities, making it highly effective for both conversational and analytical tasks.
- Meta ImageBind: Designed to link multiple modalities beyond just images and text, including audio and sensory data, offering a more comprehensive approach to multimodal AI.
- DeepMind Flamingo:- A multimodal conversational AI model capable of answering visual questions, generating captions, and maintaining dialogue grounded in visual content.
- BLIP-2 & Kosmos-1:– Research-focused VLMs pushing the boundaries of multimodal learning, enabling tasks like vision-language grounding, image-text generation, and knowledge-intensive reasoning.
6. Advantages of Vision-Language Models

Vision-Language Models (VLMs) offer a unique blend of visual and linguistic intelligence, making them highly valuable across industries. Their ability to connect images with language allows for deeper, more human-like understanding and opens doors to complex AI applications.
Key Advantages:
- Multimodal Understanding: Unlike single-modality models, VLMs can process and integrate both images and text, enabling richer insights and more accurate outputs.
- Contextual Reasoning: They understand relationships between objects and descriptions, allowing them to provide context-aware answers, captions, and decisions.
- Versatile Applications: From healthcare diagnostics to educational tools, creative content generation, and robotics, VLMs adapt to a wide variety of domains.
- Enhanced Human-AI Interaction: By interpreting visual inputs alongside natural language, they make AI interactions more intuitive and closer to real-world human communication.
- Scalable Across Use Cases: These models can be fine-tuned for specialized tasks, making them suitable for everything from e-commerce to autonomous navigation.
7. Challenges & Limitations

While Vision-Language Models (VLMs) are transforming AI, they come with significant challenges that need to be addressed before achieving their full potential.
Key Challenges:
- Bias in Training Data: VLMs are trained on massive datasets scraped from the internet, which often include biased, inaccurate, or culturally insensitive information. This can lead to models unintentionally perpetuating stereotypes or reinforcing harmful narratives.
- Ethical Concerns: The ability of VLMs to generate realistic captions, images, or videos raises concerns about deepfakes, misinformation, and privacy violations if misused.
- High Computational Costs: Developing and fine-tuning VLMs requires enormous computational power, energy consumption, and financial investment, limiting accessibility to only large organizations.
- Explainability Issues: Like other large AI models, VLMs often function as “black boxes,” making it difficult to interpret how they arrive at certain decisions, which reduces trust in critical applications like healthcare or legal systems.
- Data Quality & Security Risks: Poor-quality datasets and the lack of controlled curation can lead to inaccurate predictions and vulnerabilities to adversarial attacks.
Explore – Large Language Models
8. The Future of Vision-Language Models
The future of Vision-Language Models (VLMs) is deeply intertwined with the evolution of Artificial General Intelligence (AGI). The next generation of these systems often called Large Multimodal Models (LMMs) will go beyond just vision and language, seamlessly integrating audio, video, sensory data, and even real-world interactions to achieve more human-like understanding and reasoning.
What’s Next for VLMs?
- Reducing Biases: Through better data curation, ethical guidelines, and robust training techniques, future models will aim to minimize harmful stereotypes and ensure fairer, more inclusive outputs.
- Lightweight & Efficient Models: Development of smaller, optimized VLMs will make it possible to run these systems on edge devices like smartphones, AR/VR headsets, and IoT systems, expanding accessibility.
- Explainable AI: Future VLMs will focus on transparency, making it easier for humans to understand how models arrive at conclusions, thereby building trust in critical domains like healthcare, security, and autonomous systems.
- Multimodal Reasoning: Enhanced capabilities will allow models to combine multiple streams of data for tasks such as contextual decision-making, multimodal search, and autonomous navigation.
In essence, Vision-Language Models are paving the way for more intuitive, intelligent, and trustworthy AI systems bringing us one step closer to truly general-purpose AI.

Conclusion
Vision-Language Models represent a paradigm shift in AI, bridging the gap between what machines see and what they can describe. From personal assistants that understand images to robots that interpret their environment, VLMs are shaping the next frontier of AI innovation. For organizations partnering with SDLC CORP, these advancements open the door to building cutting-edge, multimodal AI solutions tailored for real-world applications.
Are you ready for the era where machines don’t just read or see but truly understand?
FAQs
1. How do Vision-Language Models work?
They use transformer-based architectures to process images and text together, learning connections between visual features and language through large-scale training datasets.
2. What are some real-world applications of VLMs?
They power image captioning, visual question answering, multimodal search engines, medical imaging analysis, robotics, and accessibility tools for visually impaired users.
3. Which are the leading VLMs in 2025?
Top models include OpenAI GPT-4V, Google Gemini, Meta ImageBind, DeepMind Flamingo, and research-focused models like BLIP-2 and Kosmos-1.
4. What are the key advantages of VLMs?
They provide multimodal understanding, contextual reasoning, scalability, and versatile applications across industries like healthcare, education, and robotics.
5. What challenges do VLMs face?
Challenges include bias in training data, ethical risks (like deepfakes), high computational costs, and lack of explainability in their decision-making.