

Introduction
Artificial intelligence is transforming industries, powering tools like chatbots, virtual assistants, and decision-making engines. But while AI models process massive data, they often miss the subtlety of human judgment, cultural norms, and ethical values. This creates a challenge: how can we ensure AI makes decisions that truly serve people?
This is where RLHF: Human Feedback in AI comes in. By combining reinforcement learning with direct human input, RLHF bridges the gap between machine intelligence and human expectations. It helps create AI systems that are safer, more reliable, and more aligned with real-world use.

1.What Is RLHF: Human Feedback in AI?
RLHF: Human Feedback in AI is a training technique where human evaluations guide machine learning. Instead of relying only on pre-collected data, RLHF adds a human-in-the-loop system to refine outputs. When AI generates responses, human reviewers rank them, and the system learns which ones are preferred.
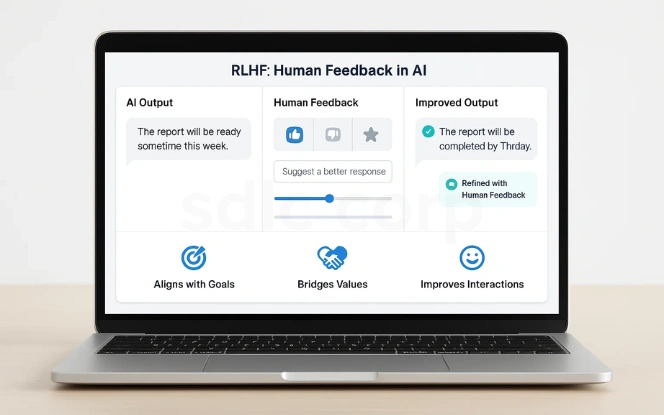
This method enables AI to capture traits that are otherwise difficult to encode, such as empathy, politeness, and helpfulness. Unlike traditional training approaches that focus solely on accuracy, RLHF prioritizes human satisfaction, making it one of the most effective techniques for AI alignment and safety.
Key Benefits of RLHF:
Aligns AI with human goals
Bridges the gap between machine learning and human values
Improves the quality of AI interactions by emphasizing traits like empathy and helpfulness
2.How RLHF Works

The process of Reinforcement Learning from Human Feedback involves multiple training stages that build on each other. It starts with pretraining the model on large datasets, but true refinement happens when humans step in to guide the model’s behavior.
Human evaluators score and rank different outputs, teaching the AI to recognize which responses are better. This data is then used to create a reward model, which acts like a compass for the AI. Finally, reinforcement learning techniques such as Proximal Policy Optimization (PPO) optimize the AI’s decision-making based on the reward model.
- Pretraining – AI learns from massive text or image datasets.
- Supervised Fine-Tuning (SFT) – Human trainers provide correct examples.
- Reward Model Training – Humans rank AI outputs to build preference signals.
- Reinforcement Learning (PPO) – AI fine-tunes its behavior to maximize rewards.
- Uses human judgment to guide machine learning.
- Builds a structured reward model.
- Makes AI safer and more aligned with people.
3.Applications of RLHF
RLHF’s influence now extends far beyond academia. For example, it already powers consumer apps, enterprise platforms, and safety-critical systems. Moreover, while conversational AI shows the most visible wins today, applications continue to expand across industries. Models like ChatGPT, GPT-4, and Google Bard rely on RLHF to produce responses that are natural and accurate. In business, it keeps chatbots compliant and on-brand. For healthcare providers, RLHF-trained assistants explain medical information clearly; meanwhile, in education, tutors adapt guidance to each learner. On the financial front, it helps advisory tools deliver recommendations that are more ethical and genuinely user-centric.

Beyond these use cases, RLHF is increasingly used in retail and e-commerce, where product recommendation systems must balance personalization with fairness. Moreover, in legal tech, RLHF helps ensure AI-driven document analysis tools remain compliant with regulations. Meanwhile, in cybersecurity, RLHF-trained models assist analysts by flagging threats while avoiding false alarms. Likewise, in content moderation, RLHF helps platforms enforce community standards more fairly and consistently.
- LLMs – GPT-4 and ChatGPT use RLHF for accurate, aligned responses.
- Customer Support – AI assistants deliver safe and polite answers.
- Healthcare & Education – Improves communication and learning outcomes.
- Finance & Retail – Ensures recommendations respect ethical standards.
- Law & Cybersecurity – Supports compliance and smarter risk management.
- Content Moderation – Balances fairness with safety in online spaces.
- Expands trust in AI across sectors.
- Adapts systems to context-specific challenges.
- Reduces risks of bias and harmful content.
4.Benefits of RLHF: Human Feedback in AI

The key advantage of RLHF is that it makes AI not just technically accurate but human-centered. A purely data-driven model might generate answers that are logical but insensitive. RLHF-trained systems, on the other hand, prioritize clarity, empathy, and usefulness.
For businesses, this means AI that customers actually want to use. Trust and adoption grow when users feel AI understands their intent and values. In high-stakes industries such as healthcare or finance, the added alignment also reduces risks, ensuring AI delivers responsible recommendations. For governments and regulators, RLHF provides a framework for building AI that respects ethical and social norms.
- Aligns AI with ethics and human expectations.
- Improves safety by reducing harmful responses.
- Enhances user experience with natural conversations.
- Builds long-term trust in AI applications.
- Helps businesses deliver consistent brand voice.
- Captures abstract qualities like honesty and empathy.
5.Challenges of RLHF
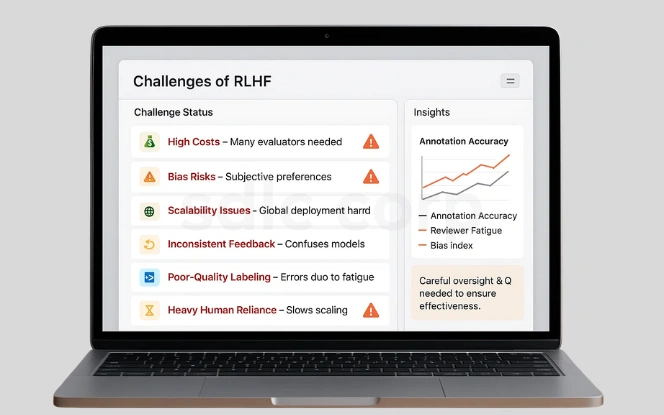
While RLHF has many benefits, it is not without its difficulties. The process depends on large numbers of human evaluators, which makes it costly and time-consuming. This creates challenges for scalability, especially for businesses deploying AI on a global level.
Human feedback is also subjective, which means biases can creep into the training process. Preferences may vary between individuals or cultures, leading to inconsistencies. For instance, an AI trained with feedback from Western evaluators may perform poorly when interacting with users in Asia, and vice versa. Annotation fatigue is another challenge—human reviewers may make mistakes or cut corners when labeling at scale. These factors make it critical to design careful oversight and quality assurance processes.
- High Costs – Requires many human evaluators.
- Bias Risks – Subjective opinions affect outcomes.
- Scalability Issues – Hard to apply everywhere at once.
- Inconsistent feedback confuses models.
- Poor-quality labeling reduces effectiveness.
- Heavy reliance on humans slows scaling.
6.The Future of RLHF and AI Alignment
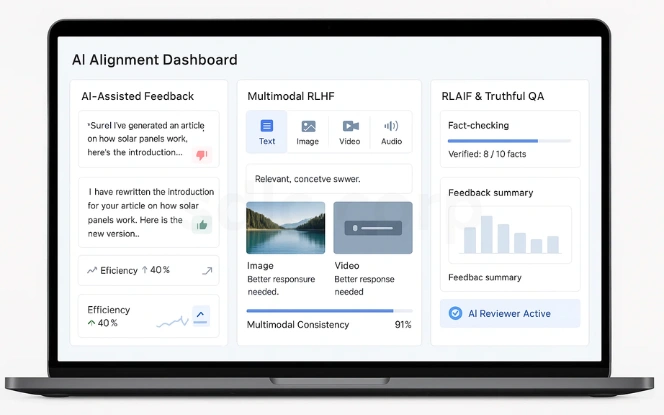
The future of RLHF: Human Feedback in AI is being shaped by innovations that reduce costs and improve scalability. One major trend is AI-assisted RLHF, where AI tools help humans evaluate outputs more efficiently. This speeds up the process while maintaining accuracy.
Multimodal RLHF is another promising area, where systems learn with feedback across text, images, video, and even audio. This approach is essential as AI evolves into multimodal platforms capable of reasoning about different types of content simultaneously. Factually augmented RLHF is also gaining traction, ensuring that human preferences are combined with truthfulness. For example, a fact-checking module can verify whether an answer is accurate before it gets ranked.
Reinforcement Learning from AI Feedback (RLAIF) is a potential game-changer, reducing the reliance on humans by using AI-generated feedback as a scalable substitute. While it raises new challenges around bias propagation, it could make alignment faster and more cost-effective. Meanwhile, researchers are exploring hybrid approaches that blend RLHF with symbolic reasoning and rule-based oversight.
7.Strategic Tips for Businesses
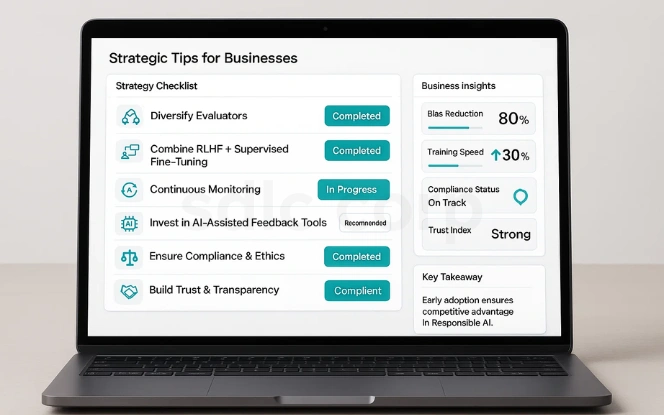
Businesses looking to implement RLHF should focus on combining efficiency with quality. A diverse group of human evaluators helps reduce bias, while continuous monitoring ensures AI stays aligned over time.
Investing in AI-assisted feedback tools can also reduce costs and improve training speed. Most importantly, companies should treat RLHF as part of a broader ethical AI strategy. When combined with compliance measures and transparency, RLHF can help businesses create safe, reliable, and competitive AI systems. Early adoption will give organizations an edge as regulators increasingly require proof of responsible AI practices.
- Diversify evaluators to minimize bias.
- Combine RLHF with supervised fine-tuning.
- Continuously monitor model performance.
- Invest in feedback-assisting AI tools.
- Ensure compliance with ethical standards.
- Focus on customer trust and transparency.

Conclusion
RLHF: Human Feedback in AI is more than a technical method; rather, it is a way of ensuring AI remains useful, ethical, and aligned with human needs. Moreover, by learning from direct feedback, AI systems become safer, more natural, and more valuable for both businesses and society.
Furthermore, organizations that adopt RLHF will be better positioned to build AI systems that are trusted, compliant, and competitive. As AI continues to shape the future, RLHF will therefore remain a cornerstone for creating technology that truly serves humanity.
Consequently, RLHF aligns AI with human values.
In addition, it builds trust in business and society.
Ultimately, it shapes the next generation of ethical AI.
Related Blogs:-
FAQ'S
What does RLHF mean in AI?
RLHF stands for Reinforcement Learning from Human Feedback. It is a training method where human evaluators guide AI systems by ranking, scoring, or choosing between different outputs. The feedback helps the AI learn not just what is technically correct, but what is most aligned with human values, preferences, and expectations. This makes the model more accurate, helpful, and context-aware.
Why is RLHF important?
RLHF is important because it improves both the safety and usefulness of AI. Traditional training methods focus only on data patterns, but RLHF adds a human layer that reduces harmful, biased, or irrelevant outputs. By integrating human judgment, RLHF makes AI systems more ethical, trustworthy, and practical for real-world applications. This alignment builds user confidence and encourages wider adoption of AI technologies.
How is RLHF used in large language models?
Large language models like ChatGPT and GPT-4 rely heavily on RLHF. During training, humans rank multiple responses generated by the AI, and the system learns which answers are most preferred. This process makes the models more conversational, polite, and accurate. As a result, RLHF enables AI to better follow instructions, reduce hallucinations, and provide context-aware answers that feel more natural and human-like.
What are the main challenges of RLHF?
Despite its benefits, RLHF faces several challenges. Training requires large numbers of human evaluators, making the process expensive and time-consuming. Human feedback can also be inconsistent or biased, leading to uneven results. Scaling RLHF to global systems is difficult, as preferences may differ across cultures. Without careful management and quality control, RLHF can reinforce biases instead of reducing them.
What is the future of RLHF?
The future of RLHF is moving toward greater efficiency and scalability. Innovations such as AI-assisted evaluation (where AI helps humans review outputs), multimodal RLHF (training across text, images, and video), and RLAIF (Reinforcement Learning from AI Feedback) are emerging. These approaches reduce the burden on human trainers while improving alignment and factual accuracy. In the long term, RLHF will continue to evolve as a cornerstone of building safe, ethical, and human-centered AI.






