Introduction
Transfer learning helps tackle small datasets by reusing pre-trained models instead of starting from scratch. But is transfer learning different than deep learning? Yes it builds on it through smart adaptation. This process, called learning transfer, boosts performance with less data. In NLP, techniques like parameter-efficient transfer learning for NLP make fine-tuning large models faster and cheaper.
Explore how transfer learning fits into modern AI development strategies to maximize efficiency and innovation.

1. Understanding Transfer Learning Fundamentals
1. What Makes Transfer Learning Revolutionary
Transfer Learning isn’t just another ML technique – it’s a complete game-changer. Think of it like this: instead of teaching someone to cook from scratch, you’re starting with a chef who already knows knife skills and basic techniques.
The revolutionary aspect? You don’t need to reinvent the wheel with every new problem. Pre-trained models have already learned to recognize edges, shapes, and patterns from millions of examples. Your job is just to fine-tune that knowledge for your specific task.
Before transfer learning, we needed massive datasets and computing resources for each new problem. Now? A model trained on ImageNet can be repurposed to identify cancer cells or analyze satellite imagery with just a fraction of the data and training time.
2. How Pre-trained Models Save Time and Resources
Imagine building a house. Would you create your own bricks from scratch or buy ready-made ones? Pre-trained models are those ready-made bricks.
Training a model from zero can take weeks on multiple GPUs and cost thousands in compute resources. With transfer learning, you can slash that to hours or even minutes on a single machine.
Look at these real-world savings:
| Training Method | Training Time | Data Needed | GPU Cost |
|---|---|---|---|
| Training from Scratch | 5–7 days | 50,000+ examples | $1,000–$3,000 |
| Transfer Learning | 2–3 hours | 500–1,000 examples | $50–$100 |
The bottom line? Transfer learning makes AI accessible to those without Google-sized budgets.
3. When Transfer Learning Outperforms Training from Scratch
Transfer learning isn’t just faster – it’s often better. When does it really shine?
- Small datasets: Got only a few hundred examples? Transfer learning will crush training from scratch.
- Similar domains: Using an image model pre-trained on natural photographs to classify medical images works surprisingly well.
- Complex problems: Some problems are just too hard to learn without prior knowledge.
The magic happens when the pre-trained model has learned general features that apply to your specific problem. Even when domains seem different (like going from natural images to X-rays), the low-level feature detection often transfers beautifully.
1.4 The Mathematics Behind Knowledge Transfer
Transfer learning works because early neural layers learn general features like edges and textures. The core idea is:
P(Y|X) = P(Y|F(X)),
where F(X) is the feature extractor from a pre-trained model. You reuse these features to map to your own targets, saving time and boosting accuracy. It’s smart math powering smarter models.
Also Read = Introduction to Machine Learning
2. Popular Pre-trained Models Worth Mastering
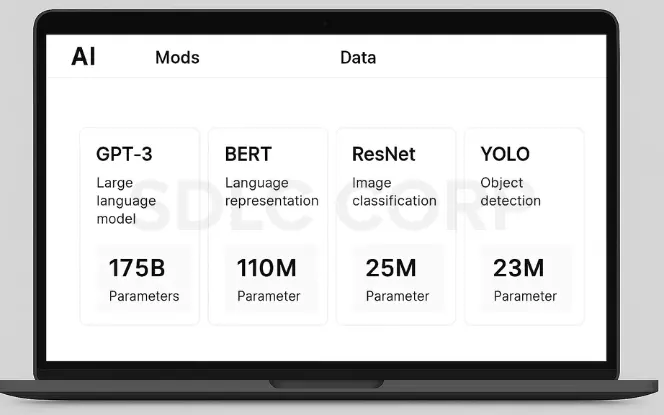
1. Image-based Models: ResNet, VGG, and Inception
Ever tried to build an image classifier from scratch? Yeah, it’s a pain. That’s why most AI practitioners don’t bother anymore. They grab pre-trained models instead.
ResNet is the workhorse of the computer vision world. What makes it special? Those “skip connections” that let information jump ahead, solving the vanishing gradient problem that plagued deep networks. ResNet-50 is probably sitting in your code right now if you’re doing any serious image work.
VGG is older but still kicking. It’s beautifully simple – just stacked 3×3 convolutions getting deeper and deeper. Sure, it’s computationally expensive, but sometimes that simplicity makes it perfect for feature extraction or transfer learning projects.
Then there’s Inception (or GoogLeNet). This clever architecture uses different kernel sizes in parallel. It’s like having multiple experts looking at your image in different ways at once. The result? Excellent performance with fewer parameters than you’d expect.
2. Natural Language Models: BERT, GPT, and RoBERTa
NLP has completely transformed in recent years. If you’re not using these models, you’re living in the past.
BERT changed everything by looking at words in context from both directions. Before BERT, models only looked at text from left to right. BERT says, “Nope, I need to see everything at once.” That’s why it crushes tasks like question-answering and sentiment analysis.
GPT took a different approach – it’s all about predicting what comes next. Each generation has gotten scarily better. GPT-4 can write essays, code, and even crack jokes that aren’t terrible. It’s trained on so much text it sometimes feels like it knows everything.
RoBERTa is basically BERT’s cooler cousin. Same core design, but trained longer, on more data, with better methods. The results speak for themselves – it outperforms BERT on almost every benchmark.
3. Multi-modal Models: CLIP and DALL-E
The coolest kids on the block understand both images and text together.
CLIP is mind-blowing because it learns from image-text pairs found across the internet. No hand-labeled datasets needed. Show it an image, and it can match it with the right description from options it’s never seen before. Or give it text and it’ll pick the matching image. The zero-shot capabilities are what make it special.
DALL-E took things further by generating images from text descriptions. Want a “teddy bear riding a skateboard in Times Square”? DALL-E will make it for you, often with surprising detail and creativity. Each version gets better at understanding nuance, style, and composition.
These multi-modal models are changing what’s possible. They’re breaking down the walls between different types of data, opening up applications we couldn’t have imagined just a few years ago.
3. Implementing Transfer Learning in Your Projects
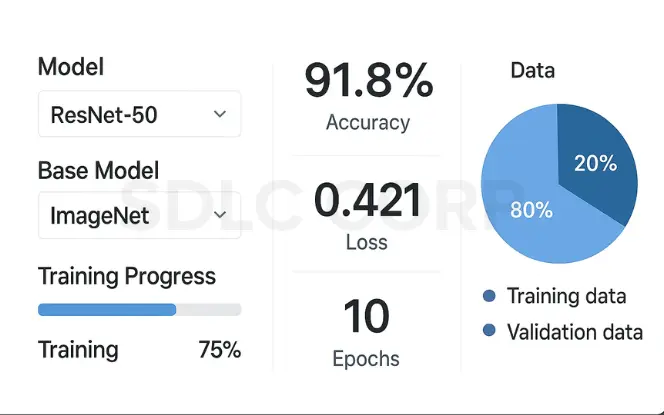
1. Choosing the Right Base Model
Picking the right pre-trained model is like choosing the right tool for a job. You wouldn’t use a hammer to tighten a screw, right?
First, consider your task domain. Working with images? Models like ResNet, VGG, or EfficientNet might be your go-to options. Tackling NLP? BERT, GPT, or RoBERTa could be better fits.
Next, think about model size versus your computational resources. Sure, that massive BERT-large might give slightly better results, but can your laptop handle it without catching fire? Sometimes a smaller, efficient model works just fine.
Also check how similar your target task is to what the model was originally trained on. A model pre-trained on natural images might struggle with medical scans unless you do some serious fine-tuning.
2. Feature Extraction vs. Fine-tuning Approaches
Got two main options here, and they’re pretty different:
Feature Extraction: Think of this as using the pre-trained model as a smart camera. You’re just extracting features without changing the model itself. It’s fast, computationally cheap, and works great when your data looks similar to what the model was trained on.
Fine-tuning: This is where you adjust the pre-trained weights to better fit your specific task. You can fine-tune the entire model or just the last few layers.
| Approach | When to Use | Computational Cost | Training Data Needed |
|---|---|---|---|
| Feature Extraction | Similar domains, limited compute | Low | Less |
| Fine-tuning | Different domains, complex tasks | Higher | More |
3. Handling Domain Shifts Between Source and Target Data
Domain shifts are the worst. Your fancy ImageNet model suddenly falls apart when trying to classify underwater images.
One trick is to use domain adaptation techniques. These help bridge the gap between your source domain (what the model was trained on) and your target domain (what you’re using it for).
Gradual fine-tuning works wonders too. Start by freezing most layers, then progressively unfreeze and train deeper layers as performance improves.
Data augmentation is another lifesaver. By creating variations of your training data, you can make your model more robust to domain differences.
4. Transfer Learning with Limited Data
We’ve all been there – awesome problem, tiny dataset.
Data augmentation becomes your best friend here. Flip, rotate, scale, add noise – anything to artificially expand your training examples without collecting more data.
Regularization techniques like dropout and weight decay are crucial too. They prevent your model from memorizing the few examples you have.
One-shot or few-shot learning approaches can also help. These methods are specifically designed to learn from minimal examples by leveraging the pre-trained knowledge.
5. Optimizing Model Parameters During Fine-tuning
Fine-tuning is an art, not just a science.
Start with a lower learning rate than you’d use for training from scratch. Your pre-trained model already has good weights – you don’t want to destroy that knowledge with aggressive updates.
Layer-wise learning rates often work better than a single rate for the whole model. Earlier layers (more general features) need smaller learning rates than later layers (more task-specific features).
Progressive unfreezing is another smart move. Start by training just the final layer, then gradually unfreeze and train earlier layers.
Monitor validation performance closely. Fine-tuning can lead to quick overfitting, especially with small datasets.
4. Advanced Transfer Learning Techniques
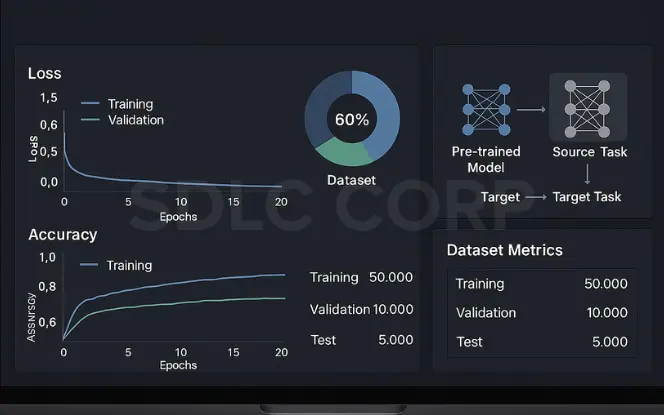
1. Progressive Neural Architecture Search
Finding the right model architecture is like hunting for a needle in a haystack. But what if you could let algorithms do the heavy lifting?
Progressive Neural Architecture Search (PNAS) takes transfer learning to another level by automating the discovery of optimal neural network architectures. Instead of manually designing networks, PNAS progressively searches through the design space, starting with simple models and gradually increasing complexity.
The magic happens when PNAS learns from previous searches. It doesn’t just randomly try architectures – it gets smarter with each iteration. This approach is typically 5-8x more efficient than random search methods.
Here’s what makes PNAS stand out:
| Feature | Benefit |
|---|---|
| Progressive search | Explores simple models first, saving computation |
| Predictive model | Estimates performance without full training |
| Transfer knowledge | Applies insights from previous models to new ones |
2. Knowledge Distillation for Model Compression
Ever tried squeezing a massive suitcase into a tiny car trunk? That’s what knowledge distillation does with huge models.
Knowledge distillation transfers the “wisdom” from a large, complex teacher model to a smaller, faster student model. The student isn’t just copying the teacher’s final outputs – it’s learning the subtle nuances in the probability distributions.
The technique works because those soft probabilities contain richer information than hard labels. When a teacher model gives 60% confidence for “cat” and 40% for “dog,” that uncertainty carries valuable information the student can learn from.
3. Cross-domain Transfer Learning Strategies
Domain gaps can wreck your transfer learning efforts. Imagine training on professional photography then testing on blurry smartphone pics – yikes!
Cross-domain transfer learning tackles this head-on with clever strategies:
- Domain adaptation techniques align feature distributions between source and target domains, making models more robust to domain shifts.
- Adversarial training pits domain classifiers against feature extractors, forcing the model to learn domain-invariant representations.
- Meta-learning approaches teach models “how to learn” across domains rather than just transferring knowledge directly.
- Few-shot learning methods transfer knowledge when target domain data is scarce.
The best practitioners mix and match these techniques depending on how different their domains are.
5. Measuring Transfer Learning Success
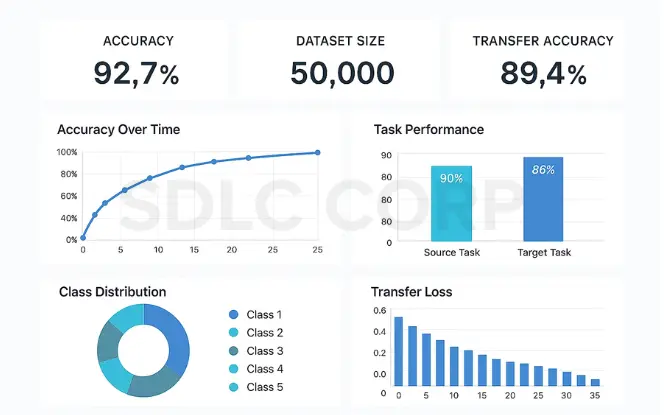
1. Evaluation Metrics That Matter
Getting transfer learning right isn’t just about copying models it’s about knowing if they actually worked. Here’s what really counts:
- Accuracy: The basic “how often is my model right?” metric
- F1 Score: Balances precision and recall—super important when your classes are imbalanced
- AUC-ROC: Shows how well your model distinguishes between classes
- Transfer Efficiency: How much data your model needs compared to training from scratch
Don’t just track- final performance. Watch how fast your model learns too. A good transfer should need less data and fewer epochs to reach decent performance.
2. Comparing Performance Against Baselines
Ever spent weeks on transfer learning only to find a simple model works better? Avoid that pain. Always compare against:
- Random initialization (no transfer)
- Simple models (sometimes a logistic regression works fine)
- State-of-the-art models in your domain
- Different pre-trained sources
The gap between your transfer model and these baselines tells the real story. If that gap is tiny, you might be wasting the computer.
3. Identifying When Transfer Learning Fails
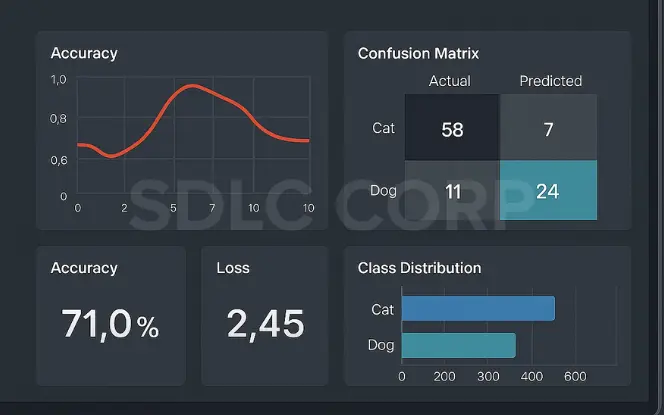
Transfer learning isn’t magic. It crashes and burns when:
- Your target task is too different from the source domain
- Your dataset is tiny (like, really tiny)
- Your fine-tuning approach is too aggressive and wipes out useful features
- The source model wasn’t that good to begin with
The warning sign? Your model quickly plateaus or even gets worse during fine-tuning.
4. Troubleshooting Common Transfer Learning Issues
Hitting a wall? Try these fixes:
- Catastrophic forgetting: Use gradual unfreezing of layers instead of training everything at once
- Negative transfer: Try layer-by-layer fine-tuning to identify which parts help vs. hurt
- Overfitting: Increase regularization specifically for the new layers
- Poor convergence: Adjust learning rates separately for pre-trained and new layers
Sometimes the fix is structural maybe you need to keep more of the original architecture intact, or maybe you need to completely rebuild the top layers.
Also Read = large language models
Conclusion
Transfer learning lets you solve new problems efficiently by building on existing models like ResNet or BERT. With the right transfer learning techniques, you can cut training time, save resources, and boost results. Instead of starting from scratch, use pre-trained models as a smart foundation balancing general knowledge with your task’s specific needs. Learn more at SDLC Corp.
FAQs
Q1. What is transfer learning in machine learning?
Transfer learning is a technique where a model trained on one task is reused (either fully or partially) for a different but related task. Instead of training a model from scratch, you leverage the “learned knowledge” from a pre-trained model to improve learning efficiency and performance on your specific task.
Q2. When should I use transfer learning instead of training a model from scratch?
Use transfer learning when:
- You have limited labeled data
- Your task is similar to the source task the pre-trained model was trained on
- You want to reduce training time and costs
- You’re working on complex tasks (e.g., medical imaging, NLP) that benefit from pre-learned feature representations
Q3. What’s the difference between feature extraction and fine-tuning in transfer learning?
- Feature extraction uses the pre-trained model as-is to extract meaningful features from input data. Only the new classifier (e.g., final layer) is trained.
- Fine-tuning involves re-training part or all of the pre-trained model to better adapt to your new task, often yielding better performance for different domains.
Q4. What are some popular pre-trained models used in transfer learning?
- Computer Vision: ResNet, VGG, Inception, EfficientNet
- Natural Language Processing: BERT, GPT, RoBERTa, DistilBERT
- Multi-modal: CLIP, DALL·E (for combining text and vision tasks)
Q5. How does transfer learning save computational resources?
Instead of training deep models from scratch (which requires vast data and GPU time), transfer learning uses already trained models as a starting point. This reduces training time from days to hours and lowers the need for expensive hardware.
Q6. Is transfer learning always better than training from scratch?
Not always. Transfer learning excels with small datasets, similar tasks, or limited resources. However, if you have plenty of domain-specific data and compute power, training from scratch may yield better performance.
Q7. What challenges can arise when using transfer learning?
- Domain shift: Differences between source and target data
Negative transfer: Transferring irrelevant features that harm performance - Overfitting: Especially when fine-tuning on small datasets
- Catastrophic forgetting: Losing pre-trained knowledge during fine-tuning
Q8. Can I use transfer learning on completely different domains?
Yes, but with caution. Cross-domain transfer is possible using techniques like domain adaptation, adversarial learning, or few-shot learning. However, performance may drop if the domains are too different without additional adjustments.
Q9. What are good practices to improve transfer learning results?
- Use data augmentation to expand your dataset
- Apply regularization techniques (like dropout, weight decay)
- Start with lower learning rates for pre-trained layers
- Use progressive unfreezing of layers during fine-tuning
- Evaluate frequently against baseline models