Introduction
Convolutional Neural Networks (CNNs) are a specialized type of deep learning model designed to process and analyze visual data. Inspired by how the human brain processes images, CNNs can automatically detect patterns like edges, shapes, and textures making them ideal for tasks like image classification, object detection, and facial recognition.
In today’s AI-driven world, CNNs are at the core of many breakthroughs in image and video analysis, powering applications in healthcare, autonomous vehicles, surveillance, and social media. Their ability to extract features from raw pixel data with minimal preprocessing makes them a cornerstone of modern AI development services.

1. What is a Convolutional Neural Network (CNN)?
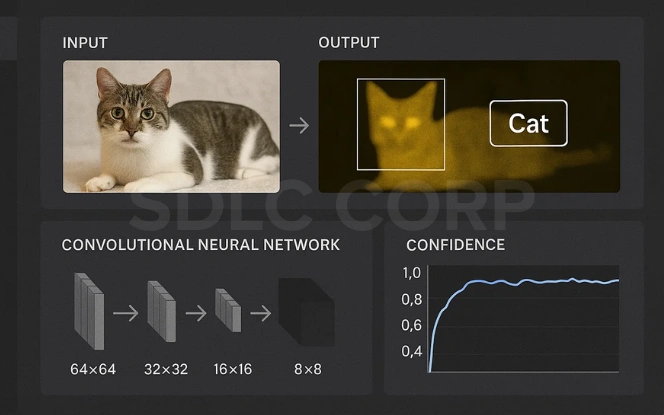
Imagine trying to teach a computer to recognize a cat in a photo. Instead of manually describing what a cat looks like, whiskers, ears, tail, a Convolutional Neural Network (CNN) learns to identify these features on its own by looking at thousands of examples. A CNN is a type of artificial neural network designed to automatically and adaptively learn spatial hierarchies of features from images, just like how our brain processes visual information.
Think of it like a smart scanner that looks at small patches of an image and asks, “Is there a pattern here I’ve seen before?” It starts by detecting simple edges and shapes and gradually builds up to recognizing complex features like eyes or faces.
Basic Components of CNNs
CNNs are made up of several building blocks, each serving a distinct role in processing data:
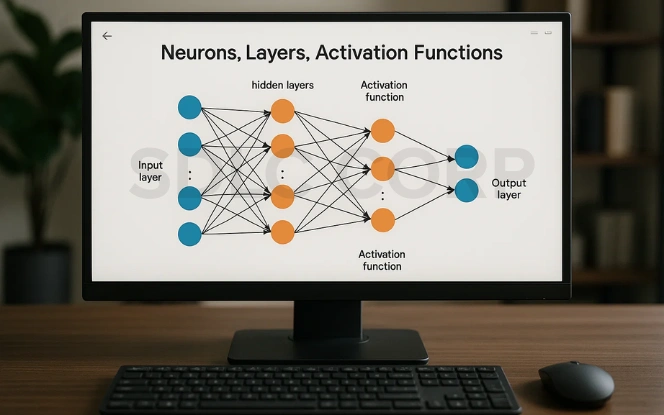
1. Neurons
- The basic processing units, inspired by biological neurons.
- Each neuron takes input, applies weights, and produces an output.
2. Layers
- Input Layer: Accepts raw image data (e.g., a 28×28 pixel grayscale image).
- Convolutional Layer: Applies filters (kernels) to extract features such as edges or textures.
- Activation Layer (ReLU): Introduces non-linearity to help the network learn complex patterns.
- Pooling Layer: Downsamples the feature maps to reduce computational load and retain essential information.
- Fully Connected Layer: Connects every neuron and performs the final classification.
- Output Layer: Uses softmax or sigmoid functions to predict class labels.
3. Weights
- Learnable parameters adjusted during training.
- They determine how important each input is in making predictions.
4. Activation Functions
- Decide whether a neuron should “fire” or not.
- Common ones: ReLU, Sigmoid, and Tanh.
CNNs vs. Traditional Feedforward Neural Networks
While both CNNs and traditional feedforward neural networks (also called Multi-Layer Perceptrons or MLPs) are used for deep learning, they differ in how they handle data:
| Feature | CNNs | Feedforward Neural Networks |
|---|---|---|
| Input Type | Best for images and spatial data | Generic input (flat features) |
| Feature Extraction | Automatic (via convolutions) | Manual or requires feature engineering |
| Weight Sharing | Yes (same filter used across image) | No (each input has a unique weight) |
| Spatial Information | Preserved (uses local patterns) | Lost (requires flattening input) |
| Parameters | Fewer (due to shared weights) | Many more (more prone to overfitting) |
2. The Architecture of CNNs

Convolutional Neural Networks (CNNs) are built with a sequence of specialized layers that transform raw image data into meaningful output like classifying whether a picture contains a dog or a cat. Each layer has a specific role, and together they make CNNs highly efficient for visual tasks
1. Input Layer – Image Representation
The input layer receives the raw image data. Images are represented as pixel values in 2D (grayscale) or 3D (color).
For example:
- A grayscale image of 28×28 pixels = 28×28 matrix
- A color image = 28x28x3 (for RGB channels)
This layer doesn’t perform any computation; it simply passes the data to the next layer.
2. Convolutional Layer – Filters and Feature Maps
This is the core building block of CNNs. The convolutional layer uses filters (or kernels) small matrices (e.g., 3×3 or 5×5) that slide over the image to detect features like edges, textures, or curves.
Each filter creates a feature map that highlights specific patterns within the image.
Key terms:
- Stride: Number of pixels the filter moves at each step.
- Padding: Adding extra pixels around the image to preserve size.
3. ReLU Activation – Introducing Non-Linearity
After convolution, the ReLU (Rectified Linear Unit) activation function is applied to the feature map. ReLU replaces all negative values with zero, adding non-linearity to the model.
This is crucial because real-world data is complex and often non-linear ReLU helps CNNs capture this complexity.
4. Pooling Layer – Downsampling Features
Pooling layers reduce the spatial size of the feature maps while retaining the most important information. This helps make the network more computationally efficient and less prone to overfitting.
Types:
- Max Pooling: Takes the maximum value from each patch of the feature map.
- Average Pooling: Takes the average value.
5. Softmax Output Layer – Final Prediction
The final layer is typically a Softmax layer in classification tasks. It converts the raw scores from the last fully connected layer into probabilities that sum up to 1.
For example, if the model is trying to classify an image into one of three classes (cat, dog, bird), the softmax output might be:
- Cat: 0.10
- Dog: 0.85
- Bird: 0.05
This allows the model to predict the most likely class with confidence.
Also read – Agentic AI Fundamentals
3. How CNNs Work – Step-by-Step

Understanding how CNNs function under the hood helps demystify their power. Rather than treating an image as a flat set of numbers, CNNs learn to identify patterns, shapes, and structures layer by layer, much like how the human visual system recognizes objects in the real world.
Let’s break down the CNN workflow step by step:
Step 1: Feature Extraction
At the heart of CNNs is their ability to automatically extract meaningful features from input images.
- When an image is passed through the convolutional layers, each filter scans across small regions (called receptive fields).
- These filters capture low-level features like edges, lines, and corners in the early layers.
- As more layers are stacked, higher-level features (e.g., eyes, shapes, faces) are extracted.
This process helps the model learn what to look for in an image without manual feature engineering.
Step 2: Learning Spatial Hierarchies
CNNs are designed to recognize patterns hierarchically:
- Early layers focus on fine details (lines, colors, edges).
- Middle layers combine low-level features into patterns (e.g., nose, fur).
- Deeper layers recognize entire structures (e.g., dog, bicycle).
By stacking multiple convolutional and pooling layers, CNNs learn spatial hierarchical relationships between parts of an object and their positions within the image. This is why CNNs are especially powerful in object recognition and image classification.
Step 3: Reduction in Dimensionality
To make computation manageable and focus on the most important information, CNNs employ techniques to reduce dimensionality.
- Pooling layers (like max pooling) downsample the feature maps.
- This reduces the number of pixels (and thus the computational load) while retaining key features.
- Minimizes overfitting.
- Speeds up training.
- Makes the model more generalizable.
Step 4: Weight Sharing and Parameter Efficiency
One of the most ingenious design choices in CNNs is weight sharing.
- Traditional neural networks assign unique weights to every connection, which can lead to millions of parameters for image inputs.
- CNNs reuse the same filter across an image, meaning the same weights are applied to different regions of the input.
This concept of weight sharing provides:
- Drastic reduction in parameters (making CNNs faster and more memory-efficient).
- Translation invariance, allowing CNNs to recognize patterns no matter where they appear in the image.
For example, a filter trained to detect a “circle” can find circles in the top-left or bottom-right of an image equally well.
Final Output
Once features are extracted, pooled, and flattened, the fully connected layers perform classification based on all learned patterns. The final output layer (often a Softmax) gives a probability distribution over possible labels.
In short CNNs work by:
- Detecting patterns (features) at various levels,
- Condensing those patterns into meaningful representations,
- Making efficient use of parameters,
- And finally predicting the most likely class with high accuracy.
4. Popular Applications of CNNs

Convolutional Neural Networks have revolutionized the field of computer vision by enabling machines to interpret visual data with remarkable accuracy. Their ability to extract and learn patterns from images makes them ideal for a wide range of real-world applications.
Key Applications:
- Image Classification
Distinguish between different categories, such as classifying images of cats vs. dogs. - Object Detection
Identify and locate multiple objects within an image using models like YOLO (You Only Look Once) and SSD (Single Shot Multibox Detector). - Face Recognition
Match and verify human faces in security systems, smartphones, and social media tagging. - Medical Imaging
Detect anomalies in X-rays, MRIs, and CT scans — aiding in early diagnosis of diseases. - Self-Driving Cars
Analyze road signs, lane markings, pedestrians, and vehicles to make real-time driving decisions.
5. Key CNN Architectures You Should Know
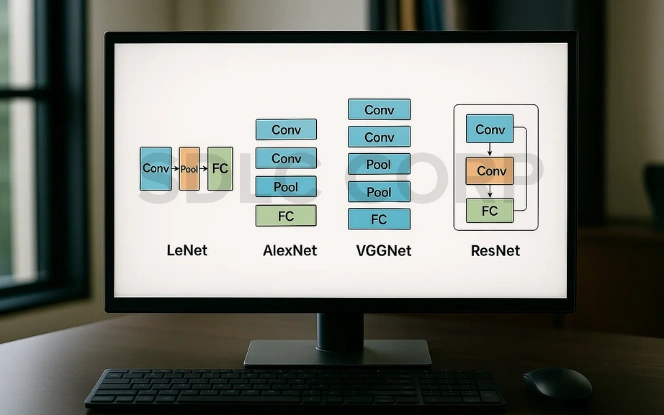
Over the years, several CNN architectures have significantly advanced the field of deep learning, each improving accuracy, depth, or efficiency. Here are some of the most influential CNN models that every AI enthusiast should know:
Notable Architectures:
- LeNet-5 (1998)
The pioneer of CNNs, designed for digit recognition (e.g., handwritten digits in the MNIST dataset). - AlexNet (2012)
Revolutionized deep learning by winning the ImageNet competition with a deep architecture and ReLU activation. - VGGNet (2014)
Introduced simplicity through uniform 3×3 convolution filters and very deep networks (16–19 layers). - GoogLeNet (Inception Network, 2014)
Efficient and deeper using inception modules allowing multi-scale feature extraction within a layer. - ResNet (2015)
Solved the vanishing gradient problem with skip (residual) connections, enabling networks with 100+ layers.
Also read – Transfer Learning Essentials
6. Advantages and Limitations of CNNs

Convolutional Neural Networks offer powerful capabilities for image and pattern recognition tasks, but like all technologies, they come with trade-offs. Understanding both their strengths and weaknesses is key to using them effectively.
Advantages:
- High Accuracy
CNNs consistently outperform traditional models in image and video tasks. - Spatial Invariance
They can detect patterns regardless of their position in the image. - Fewer Parameters
Through weight sharing, CNNs use significantly fewer parameters than fully connected networks, making training more efficient.
Limitations:
- Computationally Expensive
Training deep CNNs requires powerful GPUs and substantial memory. - Require Large Datasets
Performance often depends on access to large, labeled datasets. - Lack of Interpretability
CNNs operate as “black boxes,” making it hard to explain why they make certain predictions.
7. CNNs in Practice: Tools & Frameworks

Implementing Convolutional Neural Networks has become more accessible than ever, thanks to user-friendly libraries and frameworks. These tools simplify the process of building, training, and deploying CNN models, even for beginners.
Popular Tools & Frameworks:
- Python
The most widely used language in the AI/ML community, offering extensive support for data handling and modeling. - TensorFlow
A powerful, scalable deep learning library developed by Google. Ideal for building production-grade CNNs and deploying them across platforms. - PyTorch
Developed by Facebook, it’s known for its dynamic computation graph and intuitive syntax great for research and experimentation. - Keras
A high-level API that runs on top of TensorFlow, making it extremely beginner-friendly for designing CNN models with just a few lines of code.
8. Future of CNNs
While Convolutional Neural Networks have already transformed the field of computer vision, their evolution is far from over. Researchers and developers are exploring innovative ways to enhance CNN capabilities, making them more adaptive, efficient, and suitable for emerging real-world applications.
Emerging Trends and Directions:
- Hybrid Architectures
Combining CNNs with Recurrent Neural Networks (RNNs) or Transformers is opening new possibilities in video analysis, scene understanding, and sequential image processing. - Vision Transformers (ViTs)
A new class of models replacing convolution with self-attention mechanisms. ViTs are challenging CNN dominance in large-scale image classification tasks. - Capsule Networks
Proposed as an improvement over CNNs for preserving spatial hierarchies more effectively and reducing the need for massive data. - Real-time Processing and Edge AI
CNNs are being optimized for low-latency inference on devices like smartphones, drones, and IoT hardware, enabling on-device intelligence without cloud dependency.

Conclusion
Convolutional Neural Networks (CNNs) have transformed how machines interpret visual data, powering key innovations in image recognition, medical imaging, and autonomous vehicles. Their efficiency and accuracy make them a core component of modern AI development company.
As AI evolves, CNNs continue to inspire hybrid models and real-time applications. Exploring hands-on projects with tools like TensorFlow or PyTorch is a great way to grasp their impact and a vital step for anyone building the future of AI.
FAQs
1. What is a Convolutional Neural Network (CNN)?
A CNN is a deep learning algorithm designed to process structured grid data like images. It automatically learns to detect features (such as edges, textures, and shapes) from input images using layers of filters, pooling, and non-linear activations, ultimately enabling tasks like image classification or object detection.
2. How is a CNN different from a traditional neural network?
Unlike traditional feedforward neural networks, CNNs use convolutional layers with shared weights and local receptive fields. This design allows CNNs to retain spatial relationships in image data and drastically reduce the number of parameters, making them more efficient and effective for visual tasks.
3. What are some real-world applications of CNNs?
CNNs are widely used in:
- Facial recognition (e.g., Face ID)
- Autonomous vehicles (lane detection, obstacle recognition)
- Medical imaging (tumor detection, X-ray analysis)
- Security systems (surveillance object tracking)
- E-commerce (visual product search)
4. Which tools or libraries are best for building CNNs?
Popular tools include:
- TensorFlow – for scalable model development and deployment
- Keras – beginner-friendly high-level API (runs on TensorFlow)
- PyTorch – flexible and preferred for research
- OpenCV – often used for preprocessing image data
5. Do CNNs require large datasets to perform well?
Yes, CNNs typically perform best with large and diverse datasets. This helps the network generalize well and learn robust features. However, techniques like transfer learning and data augmentation can improve performance even when working with smaller datasets.