Introduction
Artificial Intelligence (AI) is rapidly transforming how businesses handle data, personalization, and customer experiences. A crucial technology powering this shift is the vector database. Unlike traditional databases designed for structured tables and rows, vector databases store and search high-dimensional vector embeddings numerical representations of text, images, videos, 3D models, and even sensor data.
This makes them indispensable for semantic search, recommendation systems, Generative AI (GenAI), retrieval-augmented generation (RAG), and other advanced AI-driven workflows.
If you’re exploring AI & ML implementation in your enterprise, understanding vector databases is key.
Related: AI & ML Implementation

What is a Vector Database?
A vector database is a specialized data storage system built to handle billions of high-dimensional vectors. Each vector represents complex data like the meaning of a sentence, the features of an image, or the geometry of a 3D object.
Why vectors? Machine Learning models transform raw data into embeddings—dense vectors that capture semantics. For example:
“Doctor” and “Physician” → embeddings close in vector space.
A dog image and another dog image → embeddings overlap in similarity.
Core Function: Vector databases use Approximate Nearest Neighbor (ANN) algorithms such as HNSW, IVF-PQ, and ScaNN to retrieve the most relevant results quickly, even from billions of entries.
Core AI Architecture and Data Flow
Vector databases typically sit between embedding models and application logic. They must integrate with APIs, model inference services, and downstream applications. Structured AI development services are often used to design these data flows while ensuring reliability and observability.
How Vector Databases Differ from Traditional Databases
| Feature | Vector Database | Relational DB (SQL) | Document Store (NoSQL) |
|---|---|---|---|
| Data Type | High-dimensional vectors (embeddings) | Structured tables | JSON/Key-value |
| Query | Similarity search (cosine, dot product) | Exact match / range | Keyword search |
| Scale | Billions of vectors | Millions of rows | Millions of docs |
| Speed | Millisecond ANN search | Slower for embeddings | Moderate |
| Use Case | AI apps, semantic search, GenAI | Finance, ERP | CMS, E-commerce |
For smaller projects, pgvector in PostgreSQL or Elasticsearch kNN may work. But for enterprise-scale AI, purpose-built vector databases like Pinecone, Weaviate, Milvus, or Vespa outperform alternatives.
Key Algorithms Powering Vector Databases
HNSW (Hierarchical Navigable Small World Graphs)

Creates layered graph structures for fast nearest-neighbor lookups.
Ideal for real-time search with high recall.
Used by leading databases like Weaviate and Pinecone.
IVF-PQ (Inverted File with Product Quantization)
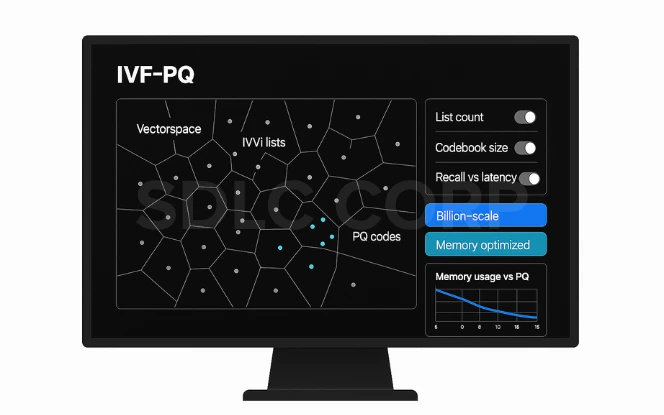
Splits vector space into buckets, reducing memory usage.
Best suited for billion-scale datasets where cost optimization matters.
ScaNN (Scalable Nearest Neighbors by Google)
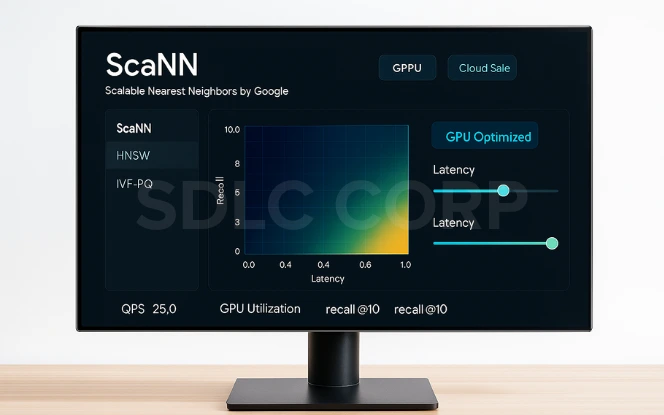
Optimized for GPUs and large-scale cloud environments.
Balances recall vs latency efficiently for modern AI workloads.
Why Vector Databases are Essential for AI Applications
Semantic Search
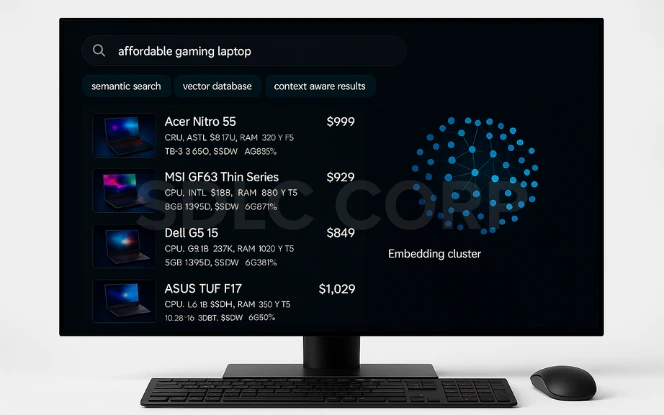
Enables context-based retrieval instead of keyword-only.
Example: “affordable gaming laptop” → retrieves budget-friendly laptops for gamers.
Related: AI Consulting Company
Retrieval-Augmented Generation (RAG)
LLMs like ChatGPT rely on vector DBs to fetch up-to-date facts.
Prevents hallucinations by grounding answers in real data.
3D Object & VR Asset Search
Essential for gaming, VR experiences, and real estate walkthroughs.
Related: 3D Modeling, VR Game Development, Hire VR Developer
Generative AI
GenAI apps retrieve embeddings to generate context-aware text, images, and designs.
Related: Hire Generative AI Developers, Generative AI in Sports Tech
Personalized Recommendations
- Streaming platforms use vector DBs for music/movie recommendations.
- E-commerce uses them for personalized product discovery.
- Related: AI in Media & Entertainment
Agriculture & Manufacturing
Identifying crop diseases, predictive maintenance for machinery.
Production Playbook: Deploying Vector Databases at Scale
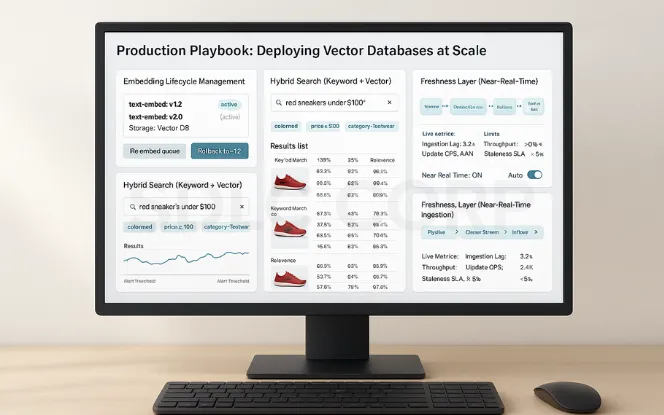
Embedding Lifecycle Management
Store embeddings with version tags.
Monitor drift when new models generate different embeddings.
Hybrid Search (Keyword + Vector)
Combine keyword filters with vector search for precision + recall.
Example: “red sneakers under $100” → keyword filter (red, $100) + vector similarity.
Freshness Layer
Use a queue-based ingestion system for near-real-time updates.
Crucial for news feeds, e-commerce inventory, or financial trading data
Observability & Monitoring
Track:
Recall@k (accuracy of results)
p95 latency (speed)
Cost per million queries (efficiency)
Cost & Scalability Considerations
Self-Hosted (FAISS, ScaNN) → Low cost, but requires DevOps & infra expertise.
pgvector → Cheap, but scales poorly beyond ~50M vectors.
Managed Vector Databases (Pinecone, Weaviate, Milvus) → Optimized for enterprise workloads.
For businesses, the sweet spot is usually a cloud-hosted vector DB—balancing scalability, performance, and predictable cost.
(Related: AI as a Service)
Security, Compliance & Governance in Vector Databases
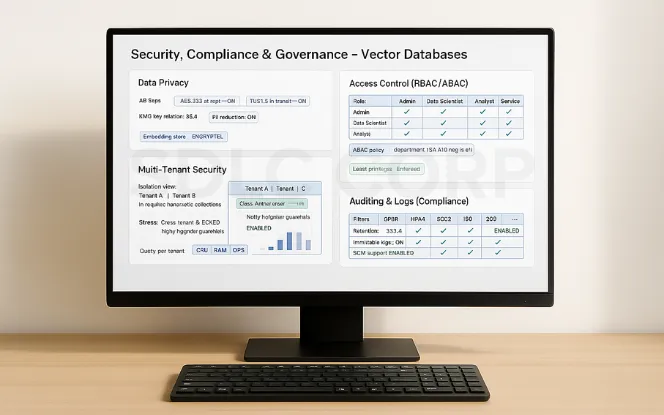
Data Privacy: Encrypt embeddings at rest and in transit.
Multi-Tenant Security: Ensure tenant isolation in SaaS deployments.
Access Control: Implement RBAC/ABAC for enterprise users.
Auditing & Logs: Track query activity for compliance (GDPR, HIPAA).
Governance and Responsible Use of Vector Data: Vector databases may store sensitive semantic representations of user data. An AI consulting company can help define governance rules for data retention, access logging, and model explainability.
These are non-negotiable for industries like healthcare, finance, and government AI.
Industry Use Cases
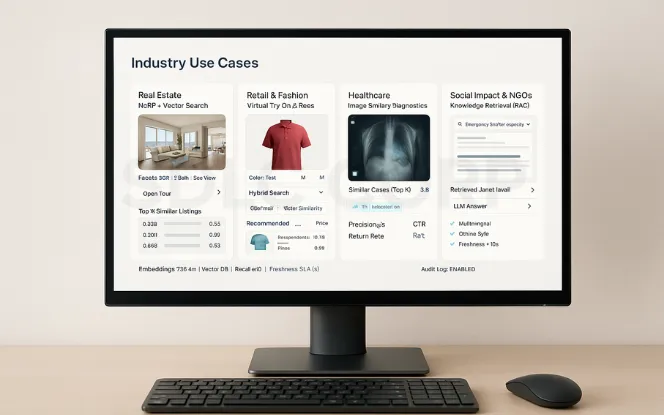
Real Estate – Virtual tours powered by NeRF + vector DB for property searches.
Retail & Fashion – Virtual fitting rooms and recommendation engines.
Healthcare – Image-based diagnostics with similarity search.
Social Impact & NGOs – Knowledge retrieval for education or disaster response. (Generative AI for Social Impact)

Enterprise-Scale Vector Data Management
Large organisations often run multiple vector workloads across departments. Practices followed by an enterprise AI development company help standardise schema design, access control, and lifecycle management.
Conclusion
Vector databases are the cornerstone of modern AI applications from semantic search to Generative AI pipelines, VR gaming, 3D modeling, and personalized recommendations. With algorithms like HNSW, IVF-PQ, and ScaNN, they strike the perfect balance of accuracy, scalability, and cost-efficiency.
If your business is building the next generation of AI-powered products, adopting a vector database strategy is essential.
For tailored guidance, explore:
FAQ'S
What is the difference between a vector database and a relational database?
Relational databases are designed for structured data, storing information in rows and tables with predefined schemas. They work best for transactional operations such as banking records, inventory, or CRM systems. Vector databases, on the other hand, store high-dimensional embeddings (mathematical representations of unstructured data like text, images, or audio). Instead of matching exact values, they enable similarity-based retrieval, making them ideal for semantic search, recommendations, and AI-driven applications.
Do I need a vector database for AI?
Yes, if your application relies on semantic understanding, personalization, or contextual retrieval at scale. For example, AI chatbots, recommendation engines, and Retrieval Augmented Generation (RAG) pipelines all depend on vector databases to provide accurate and contextually relevant results. Without them, AI systems often rely on keyword search alone, which fails to capture meaning.
Is Pinecone better than Weaviate?
It depends on your needs:
- Pinecone is a managed SaaS solution, making it easy for enterprises to deploy without worrying about infrastructure. It offers reliability, scalability, and enterprise-grade performance.
- Weaviate is an open-source option that gives developers flexibility, customization, and hybrid search (combining keyword + vector queries). It’s great for experimentation and when you need full control over your stack.
Can I use PostgreSQL with pgvector instead?
Yes, PostgreSQL with pgvector can store and query embeddings. However, it is better suited for small to medium-scale projects or prototypes. For enterprise-level applications requiring billions of vectors, low-latency searches, and advanced indexing, dedicated vector databases such as Pinecone, Milvus, or Qdrant are more efficient.
What’s the best free vector database?
Several open-source vector databases are widely used:
- Milvus – known for handling large-scale multimedia data with GPU acceleration.
- Weaviate – flexible and supports hybrid semantic + keyword search.
- Qdrant – optimized for performance, built in Rust, with strong filtering support.
- Chroma – simple, developer-friendly, and popular for small to medium AI projects.