

8 simple ways to quickly copy a table from PDF to Excel
In today’s data-driven landscape, extracting information efficiently from PDF documents and transferring it into Excel spreadsheets is a crucial task for many businesses and professionals. This process not only enhances accessibility and organization but also facilitates data analysis and decision-making. Among the various tools and methods available for this purpose, SDLCCORP stands out as a robust solution, offering streamlined conversion capabilities and seamless integration.
SDLCCORP simplifies the extraction process by leveraging advanced algorithms to accurately identify and capture data from PDF files. Its user-friendly interface allows users to specify extraction parameters and customize output formats, ensuring compatibility with Excel and other spreadsheet applications. With SDLCCORP, tedious manual data entry becomes a thing of the past, saving valuable time and resources while minimizing errors.
Moreover, integration with Google Docs further enhances the versatility and accessibility of extracted data. By seamlessly transferring PDF content to Google Docs, users can collaborate in real-time, share information effortlessly, and access files from any device with an internet connection. This integration expands the reach of extracted data, facilitating collaboration among teams and enabling efficient workflow management.
In summary, the process of extracting data from PDF to Excel with SDLCCORP offers a streamlined and efficient solution for businesses and professionals. By harnessing advanced technology and seamless integration with Google Docs, SDLCCORP empowers users to unlock the full potential of their data, driving productivity, collaboration, and informed decision-making.
Overview of 8 simple ways to quickly copy a table from PDF to Excel
Extracting data from PDF to Excel, particularly for SDLCCORP, involves several steps to ensure accurate and efficient conversion. The process typically begins with converting the content of the PDF, which may include textual data as well as images, into a format that is readable and editable for further manipulation in Excel. One crucial aspect of this process is converting PDF images to text, which enhances the accuracy and usability of the extracted data.
To initiate the extraction process, specialized software or tools are often employed. These tools utilize optical character recognition (OCR) technology to convert the text within the PDF into a digital format. OCR technology is instrumental in deciphering scanned documents or images containing text, thereby enabling the extraction of textual data even from non-editable PDFs.
Once the text has been extracted, it undergoes a thorough cleaning process to eliminate any formatting inconsistencies or errors that may have arisen during the OCR conversion. This cleaning process may involve removing unnecessary characters, correcting misspellings, and ensuring uniformity in the structure of the extracted text.
In parallel, PDF images containing textual information are subjected to OCR technology to convert the image-based text into editable text format. This conversion enhances the comprehensiveness of the extracted data by including information embedded within images, such as charts, tables, or diagrams, into the Excel spreadsheet.
In summary, the process of extracting data from PDF to Excel for SDLCCORP involves converting text and image-based content into a readable and editable format using OCR technology, cleaning and formatting the extracted data, and transferring it into an Excel spreadsheet for further analysis and utilization. By incorporating PDF image to text conversion, the process ensures comprehensive extraction of data, enabling efficient handling and utilization of information for business purposes.
Can you share your method for transferring content from a PDF to an Excel sheet?
The process of copying data from a PDF and pasting it into Excel is a common task encountered in various professional and academic settings. When dealing with PDF documents, which are often used for presenting information in a fixed-layout format, extracting data for analysis or manipulation in Excel can be a necessary step. This task involves transferring text, tables, or other structured data from a PDF document into an Excel spreadsheet.
To copy data from a PDF to Excel, one typically opens the PDF document using a compatible reader or software, selects the desired content, and then copies it to the clipboard. Upon opening Excel, the copied content can be pasted into a new or existing worksheet. However, it’s essential to note that the process may vary slightly depending on the complexity of the PDF layout and the software being used.
When copying from a PDF, it’s crucial to ensure the accuracy of the data transferred. PDF documents may contain images, scanned text, or text elements that are not recognized as editable text by the copying software. In such cases, manual adjustments or the use of specialized software may be necessary to accurately extract and transfer the data into Excel.
On the other hand, extracting data from Excel to PDF involves the reverse process—taking data from an Excel spreadsheet and embedding it into a PDF document. This task is often encountered when creating reports, forms, or presentations that require the distribution of data in a PDF format. Excel provides various options for exporting data to PDF, allowing users to customize the layout, appearance, and formatting of the resulting PDF document.
When integrating data from Excel into a PDF document, users can choose to export entire worksheets, selected ranges, or individual charts and tables. Excel’s export options typically include settings for adjusting page orientation, paper size, margins, and other formatting preferences to ensure the compatibility and readability of the resulting PDF file.
In summary, the process of copying data from a PDF and pasting it into Excel, as well as extracting data from Excel to PDF, are essential tasks that involve transferring information between two widely used formats for document management and analysis. While these processes can often be straightforward, they may require attention to detail and the use of appropriate tools to ensure the accuracy and integrity of the transferred data.
"SDLCCORP Approach: Converting PDF Data into Excel"

What are the key features and limitations of popular online PDF to Excel converters?
Certainly! Converting PDF files to Excel format is a common task, especially when dealing with data extraction or analysis. Here’s an overview of some popular online PDF to Excel converters along with details about how they function:
- Smallpdf:
– Smallpdf is a widely used online platform offering various PDF tools, including PDF to Excel conversion.
– It offers a simple drag-and-drop interface for uploading PDF files.
– Once uploaded, Smallpdf automatically converts the PDF to an Excel file.
– The extracted data is usually preserved well, including tables, text, and formatting.
- PDFTables:
– PDFTables is known for its accuracy in extracting tabular data from PDFs into Excel.
– Users can upload PDFs from various sources, including scanned documents.
– The platform employs advanced algorithms to accurately recognize tables within the PDF and convert them into an editable Excel format.
– It also offers APIs for developers who need to integrate PDF to Excel conversion into their applications.
- Soda PDF:
– Soda PDF provides a suite of PDF tools, including conversion to Excel.
– It supports batch conversion, allowing users to upload multiple PDF files for conversion at once.
– The platform ensures that the original layout and formatting of the PDF are preserved in the resulting Excel file.
– Users can also choose specific pages or ranges from the PDF to convert.
- Nitro PDF to Excel:
– Nitro offers PDF to Excel conversion as part of its broader PDF productivity suite.
– It supports both online and desktop versions.
– The online version allows users to upload PDFs and convert them to Excel quickly.
– Nitro emphasizes accuracy and fidelity in maintaining the structure of tables and text during conversion.
- OnlineOCR:
– OnlineOCR specializes in converting scanned PDFs into editable Excel files.
– It utilizes OCR (Optical Character Recognition) technology to recognize text from scanned documents.
– The platform supports multiple languages and can handle complex layouts.
– Users can upload PDFs directly from their device or provide URLs for conversion.
Extracting Data from PDF to Excel:
When using these converters, the process usually involves the following steps:
- Upload the PDF file containing the data you want to extract.
- The converter identifies tables, text, and other elements within the PDF.
- It then converts this data into an Excel-compatible format, preserving the structure and formatting as much as possible.
- You can then download the converted Excel file containing the extracted data.
- In Excel, you may need to further refine or manipulate the data as per your requirements.
Keep in mind that while these converters offer convenience and accuracy, the quality of the conversion can vary depending on factors such as the complexity of the PDF layout and the quality of the original document. It’s always a good idea to review the converted Excel file and make any necessary adjustments manually.
How to Export PDF data to Excel using Adobe Acrobat
Sure, I can provide you with a detailed overview of how to export PDF data to Excel using Adobe Acrobat, along with instructions on how to extract pages from a PDF.
Exporting PDF Data to Excel using Adobe Acrobat:
- Open the PDF in Adobe Acrobat: Launch Adobe Acrobat and open the PDF file from which you want to export data to Excel.
- Select Export Option: Go to the “Tools” tab and select “Export PDF.” This will open the Export PDF panel.
- Choose Excel Format: In the Export PDF panel, select “Spreadsheet” as the export format. Then choose “Microsoft Excel Workbook” as the file format.
- Specify Export Settings: Depending on your requirements, you may have various options to customize the export. You can choose whether to export all pages or a range of pages, select the layout options, and set other preferences.
- Export Data: Once you have configured the export settings, click on the “Export” button. Choose the location on your computer where you want to save the Excel file and give it a name. Then click “Save.”
- Open Excel File: After the export is complete, navigate to the location where you saved the Excel file and open it using Microsoft Excel or any compatible spreadsheet software. You should see the PDF data converted into an Excel spreadsheet.
Extracting Pages from PDF using Adobe Acrobat:
- Open PDF in Adobe Acrobat: Launch Adobe Acrobat and open the PDF file from which you want to extract pages.
- Access Page Thumbnails: Go to the “Tools” tab and select “Organize Pages.” This will open the Organize Pages panel.
- Select Pages to Extract: In the Organize Pages panel, you’ll see thumbnail images of each page in the PDF. Select the pages you want to extract by clicking on their thumbnails. You can select multiple pages by holding down the Ctrl (Cmd on Mac) key while clicking.
- Extract Pages: Once you have selected the pages, right-click on one of the selected thumbnails and choose “Extract Pages” from the context menu. Alternatively, you can click on the “Extract” button in the toolbar above the thumbnails.
- Specify Extraction Options: In the Extract Pages dialog box, choose whether you want to extract the selected pages as separate files or as a single PDF. You can also specify the page range if you only want to extract a portion of the document.
- Extract Pages: After specifying your extraction options, click “OK” to start the extraction process. The extracted pages will be saved as separate files or as a single PDF, depending on your selection.
- Access Extracted Pages: Navigate to the location where the extracted pages were saved and open them using Adobe Acrobat or any compatible PDF viewer.
By following these steps, you can easily export PDF data to Excel and extract pages from a PDF using Adobe Acrobat.
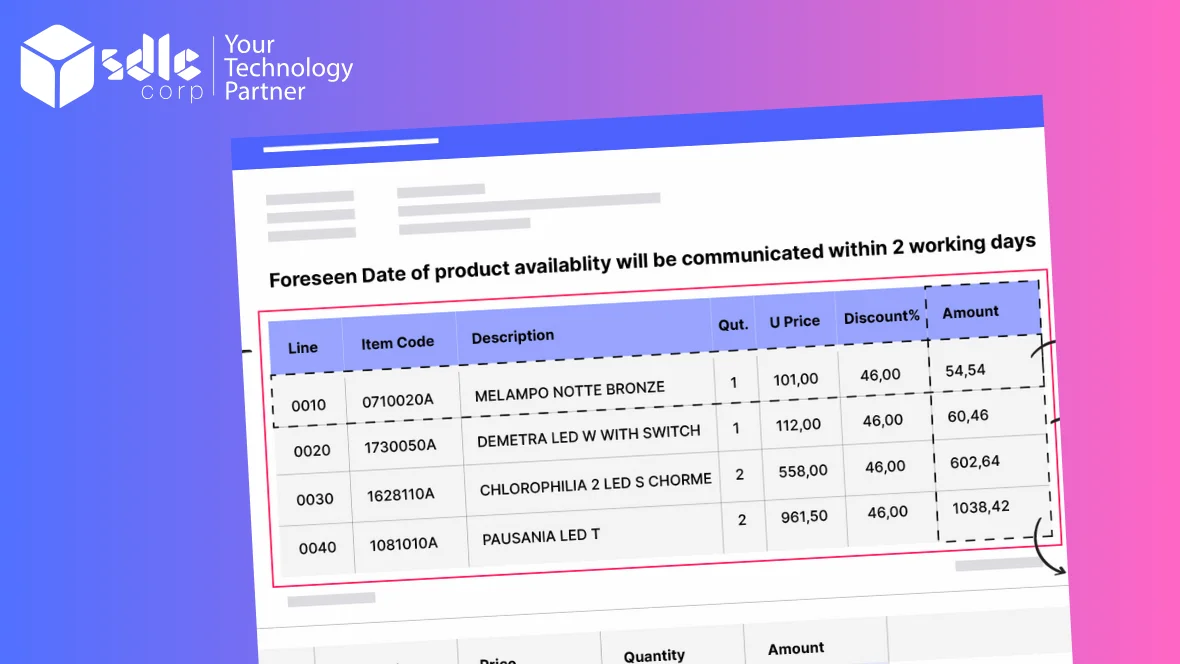
Which PDF table extraction tool do you recommend and why?
PDF table extraction tools are software applications designed to extract tabular data from PDF documents. These tools are particularly useful when dealing with large volumes of data stored in PDF format, as they automate the process of extracting tables, saving time and effort compared to manual extraction methods. Here’s a detailed overview of PDF table extraction tools:
- Tabula:
– Tabula is an open-source tool specifically designed for extracting tables from PDF documents.
– It provides a user-friendly interface for selecting and extracting tables from PDF files.
– Users can manually select table areas using a graphical interface or specify the area coordinates for extraction.
– Supports extraction to various formats such as CSV, Excel, and TSV.
– Tabula can be run as a standalone application or accessed via its API for integration into other software solutions.
- PDFTables:
– PDFTables is a web-based PDF table extraction tool that offers both manual and automated extraction options.
– Users can upload PDF files to the PDFTables website and choose between automatic or custom extraction methods.
– The automatic extraction method utilizes advanced algorithms to detect and extract tables automatically.
– Offers options for downloading extracted tables in various formats including CSV, Excel, and XML.
– PDFTables also provides an API for programmatic access to its extraction services, allowing integration with other applications.
- Camelot:
– Camelot is a Python library for extracting tables from PDF documents.
– It offers both command-line and Python API interfaces for table extraction.
– Camelot uses image processing and machine learning algorithms to detect and extract tables from PDFs.
– Provides options for specifying table regions and adjusting extraction parameters.
– Supports export to formats such as CSV, Excel, JSON, and SQLite.
– Camelot also offers a web-based GUI called Camelot Pro for users who prefer a graphical interface.
- PDFMiner:
– PDFMiner is a Python library for extracting text and data from PDF documents.
– While it doesn’t specialize in table extraction, it can be used to extract tables by analyzing the layout and structure of the PDF document.
– PDFMiner offers options for extracting text and table data programmatically using its Python API.
– It requires some level of programming knowledge to use effectively, as it operates primarily through Python scripts.
– Provides flexibility for customizing extraction methods according to specific document layouts.
- Docparser:
– Docparser is a cloud-based document parsing platform that supports PDF table extraction.
– Users can upload PDF documents to the Docparser platform, where tables are automatically detected and extracted.
– The platform offers options for customizing extraction rules and mapping extracted data to predefined fields.
– Supports integration with third-party applications via its API, allowing for automated data extraction workflows.
– Docparser provides features for processing large volumes of documents and handling complex table structures efficiently.
These tools offer varying levels of complexity, customization, and automation for extracting tables from PDF documents. The choice of tool depends on factors such as the user’s technical expertise, specific requirements, and preferred interface.
Best methods for PDF to Excel data extraction automation?
Automated data extraction from PDF to Excel involves using software tools or programming scripts to extract information from PDF files and populate it into Excel spreadsheets automatically. This process is particularly useful when dealing with large volumes of data stored in PDF documents, such as financial reports, invoices, forms, or research papers.
Here’s a detailed breakdown of how automated data extraction from PDF to Excel typically works:
- Identifying Data: The first step is to identify the data you want to extract from the PDF documents. This may include tables, text, images, or specific fields within forms.
- Choosing Extraction Tool: There are various tools available for automated data extraction from PDFs. Some popular options include Adobe Acrobat Pro, Tabula, PDFTables, Camelot, and PyPDF2. Each tool has its own set of features and capabilities, so you may need to choose one based on your specific requirements.
- Setting Extraction Parameters: Depending on the tool you’re using, you may need to configure extraction parameters such as specifying the pages to extract data from, defining table boundaries, selecting extraction formats (e.g., CSV, Excel), and setting up any necessary preprocessing steps.
- Executing Extraction: Once the parameters are set, you can execute the extraction process. The tool will scan the PDF documents according to the specified parameters and extract the relevant data into a format that can be imported into Excel.
- Data Formatting and Cleansing: Extracted data may require formatting and cleansing to ensure consistency and accuracy. This may involve removing unnecessary characters, converting data types, handling special cases, and ensuring data integrity.
- Importing into Excel: After the data is extracted and formatted, it can be imported into Excel. Most extraction tools provide options to export data directly into Excel spreadsheets or CSV files, which can then be opened and further manipulated in Excel.
- Automation: To streamline the process further, you can automate data extraction using programming languages such as Python or R. Libraries like PyPDF2, Camelot, PDFPlumber, and openpyxl in Python can be utilized to build custom scripts for automated extraction and manipulation of PDF data into Excel.
- Testing and Validation: It’s essential to thoroughly test the automated extraction process to ensure accuracy and reliability. Validate the extracted data against the original PDF documents to catch any discrepancies or errors.
- Iterative Improvement: As you continue to use the automated extraction process, you may encounter new challenges or discover areas for improvement. Iterate on your extraction workflows to optimize efficiency and accuracy over time.
Automated data extraction from PDF to Excel can significantly save time and effort, especially in industries where dealing with large volumes of data is common. However, it’s crucial to choose the right tools and methods and validate the extracted data to ensure its reliability and accuracy.
"Efficient Data Transfer: SDLCCORP's PDF-to-Excel Extraction Process"
Benefits of extract data from pdf to excel-SDLCCORP
Extracting data from PDF to Excel offers numerous benefits for businesses, especially when combined with web scraping using Python. Here’s a brief description highlighting the advantages:
- Efficiency: Extracting data from PDFs to Excel streamlines the process of data entry, saving time and resources. By automating this task through Python web scraping, businesses can achieve even greater efficiency.
- Accuracy: Manual data entry is prone to errors, but extracting data from PDFs ensures accuracy by eliminating human errors. Python web scraping further enhances accuracy by retrieving data directly from online sources with precision.
- Structured Data: PDFs often contain unstructured data, making it challenging to analyze. By converting this data into Excel, it becomes structured and easier to manipulate, analyze, and visualize. Python web scraping allows businesses to access structured data from various online platforms.
- Integration: Excel is a widely used tool for data analysis and reporting. By extracting data from PDFs to Excel, businesses can integrate this data seamlessly into existing workflows, databases, or analytics tools. Python web scraping facilitates integration by collecting data from diverse online sources.
- Automation: Manually extracting data from PDFs is time-consuming and tedious. With Python web scraping, businesses can automate the extraction process, ensuring timely updates and reducing manual effort.
- Customization: Excel provides flexibility in organizing and formatting data according to specific requirements. By extracting data from PDFs to Excel using Python web scraping, businesses can customize the format, layout, and structure of the data to suit their needs.
In summary, leveraging Python web scraping to extract data from PDFs to Excel offers businesses increased efficiency, accuracy, structured data, integration capabilities, automation, and customization options, ultimately enhancing decision-making and productivity.
Conclusion
Extracting data from PDF to Excel is a crucial process for businesses and professionals dealing with vast amounts of information stored in PDF documents. The method outlined by SDLCCorp provides a systematic approach to automate this task efficiently. By identifying the data to extract, selecting appropriate extraction tools, setting parameters, executing extraction, formatting data, and validating results, SDLCCorp’s approach ensures accuracy and reliability in the extraction process.
Automated data extraction not only saves time but also reduces errors associated with manual data entry. It enables businesses to streamline workflows, improve productivity, and make better-informed decisions based on accurate data. Additionally, by leveraging programming languages and libraries for automation, organizations can customize extraction workflows to suit their specific needs and scale the process as their requirements evolve.
In conclusion, mastering the art of extracting data from PDF to Excel empowers professionals and businesses to unlock valuable insights from their PDF documents efficiently. With the right tools, methods, and attention to detail, extracting data becomes a seamless process, enabling organizations to harness the full potential of their data assets.
FAQs
1. What tools are available for extracting data from PDF to Excel?
There are several tools available for extracting data from PDF to Excel, including Adobe Acrobat Pro, Tabula, PDFTables, Camelot, and PyPDF2. Each tool has its own set of features and capabilities, so it’s essential to choose one that suits your specific requirements.
2. Can I extract tables from PDF files and import them directly into Excel?
Yes, many extraction tools have the ability to identify tables within PDF files and extract them directly into Excel format. Tools like Camelot and Tabula, for example, specialize in extracting tables from PDF documents and exporting them into structured formats like CSV or Excel.
3. How accurate is the data extraction process?
The accuracy of data extraction from PDF to Excel depends on various factors such as the quality and formatting of the PDF documents, the extraction tool used, and any custom configurations or preprocessing steps applied. Generally, extraction tools strive for high accuracy, but it’s essential to validate the extracted data against the original PDF documents to ensure accuracy and reliability.
4. Can I automate the data extraction process to save time?
Yes, you can automate the data extraction process using programming languages like Python or specialized libraries such as PyPDF2, Camelot, and openpyxl. By writing scripts or programs, you can streamline the extraction workflow and handle large volumes of PDF files efficiently.
5. What if the PDF documents have complex layouts or non-standard formatting?
Extraction tools may struggle with complex layouts or non-standard formatting in PDF documents. In such cases, manual intervention or preprocessing steps may be necessary to ensure accurate extraction. Some tools offer advanced features for handling complex layouts, while others may require additional customization or configuration to extract data accurately.
Contact Us
Let's Talk About Your Project
- Free Consultation
- 24/7 Experts Support
- On-Time Delivery
- sales@sdlccorp.com
- +1(510-630-6507)












