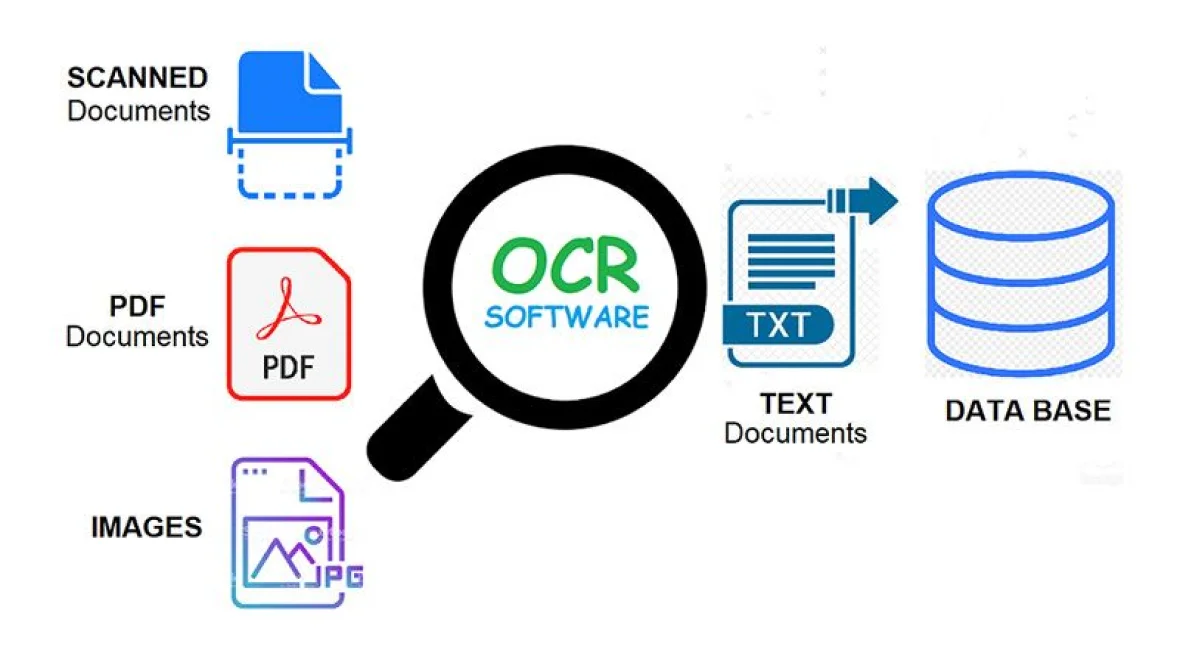
Optical Character Recognition (OCR) is a pivotal technology that enables computers to extract text from images or scanned documents, transforming visual information into editable and searchable text data. Leveraging Tesseract, an open-source OCR engine maintained by Google, alongside Python libraries such as Pytesseract and OpenCV, facilitates seamless integration of OCR capabilities into Python applications. To initiate OCR with Tesseract in Python, one must first install the requisite libraries, including Tesseract, Pytesseract, and OpenCV, utilizing package managers like pip. Once installed, the process typically involves loading an image using OpenCV, pre-processing it to enhance text clarity and remove noise, and then utilizing Pytesseract to perform OCR on the processed image. Techniques like resizing, thresholding, and image enhancement can significantly improve OCR accuracy. Moreover, Pytesseract provides a convenient interface to interact with Tesseract, allowing users to extract text from images effortlessly. Additionally, incorporating OpenCV functionalities enables advanced image manipulation and preprocessing techniques, enhancing OCR accuracy further. This comprehensive approach to OCR with Tesseract in Python, combined with Pytesseract and OpenCV, empowers developers to efficiently extract text from images and integrate this valuable functionality into various applications, streamlining tasks such as image-to-text conversion and document analysis.
How its work ?
Definition of Technology:
– Technology refers to the application of scientific knowledge for practical purposes, especially in industry and commerce. It includes tools, systems, methods, and processes used to solve problems and achieve objectives.2. Categories of Technology:
– Technology can be classified into various categories such as information technology (IT), biotechnology, nanotechnology, energy technology, communication technology, medical technology, and more.3. Working Principles:
– Each technology operates based on specific principles that govern its functionality. For example:
– Information technology relies on algorithms, data structures, and computational processes to manipulate, store, and transmit data.
– Biotechnology utilizes biological systems, organisms, or derivatives to develop products or applications for various purposes such as medicine, agriculture, and industry.
– Nanotechnology deals with structures and devices at the nanometer scale, employing materials and techniques to manipulate matter at the atomic and molecular levels.4. Components and Mechanisms:
– Technology often comprises various components and mechanisms that work together to achieve a specific task or function. These components can include hardware (physical devices), software (programs and applications), sensors, actuators, circuits, and more.
– For instance, in a computer system, the hardware components include the central processing unit (CPU), memory modules, storage devices, input/output devices, and networking interfaces. The software components encompass the operating system, application software, and drivers.5. Processes and Procedures:
– Technology involves processes and procedures designed to accomplish specific goals efficiently and effectively. These may include manufacturing processes, software development methodologies, quality assurance procedures, troubleshooting protocols, and maintenance routines.
– For example, in software development, various methodologies such as Agile, Waterfall, and DevOps dictate how teams plan, execute, and deliver software projects. These methodologies involve a series of steps, including requirements gathering, design, implementation, testing, deployment, and maintenance.6. Innovation and Advancements:
– Technology continually evolves through innovation and advancements driven by research, experimentation, and collaboration across disciplines. New discoveries, materials, techniques, and approaches lead to the development of improved technologies with enhanced capabilities, efficiency, and reliability.7. Impact and Applications:
– Technology has a profound impact on society, economy, culture, and the environment. It permeates every aspect of human life, influencing how we communicate, work, travel, learn, entertain, and healthcare. The applications of technology range from everyday consumer products to critical infrastructure systems, scientific research, space exploration, and beyond.Overall, understanding how technology works involves delving into its underlying principles, components, processes, and applications across various domains. It requires interdisciplinary knowledge and continuous learning to keep pace with the rapid advancements in technology.
"Setting up Tesseract OCR with Pytesseract and OpenCV"

To OCR (Optical Character Recognition) with Tesseract in Python using Pytesseract and OpenCV, you’ll first need to ensure you have these libraries installed in your Python environment. Pytesseract acts as a wrapper for Google’s Tesseract-OCR Engine, while OpenCV provides various image processing functionalities. Begin by importing these libraries into your Python script. Next, you’ll need to load the image you want to perform OCR on using OpenCV’s imread function. Preprocess the image if necessary; this might involve resizing, converting to grayscale, or applying filters to enhance text clarity.
Once the image is ready, pass it to the Pytesseract’s image_to_string function, which will utilize Tesseract’s OCR capabilities to extract text from the image. You can specify additional parameters like language settings or page segmentation mode according to your requirements.
After extracting the text, you can handle it further as needed. This might involve tasks such as storing the text in a variable, writing it to a file, or performing additional processing such as natural language processing tasks.
Regarding the addition of PDFs to Google Docs within this context, you can achieve this using the Google Drive API in Python. First, you’ll need to authenticate with the Google Drive API and obtain necessary permissions. Then, you can upload the PDF file to Google Doc using the API. Once uploaded, you can use the Google Docs API to create a new Google Docs document and insert the text extracted through OCR directly into this document. Make sure to handle errors and exceptions appropriately throughout this process to ensure smooth execution.
Benefits of OCR with Tesseract in Python with Pytesseract and openCV
In summary, by combining Pytesseract and OpenCV for OCR in Python, along with leveraging the Google Drive and Google Docs APIs, you can create a robust workflow for extracting text from images, including PDFs, and seamlessly integrating it into Google Docs documents.
OCR (Optical Character Recognition) with Tesseract in Python using Pytesseract and OpenCV offers a plethora of benefits, especially when it comes to importing PDF data into Excel. Here’s a detailed look at the advantages:
- Accuracy: Tesseract, coupled with Pytesseract and OpenCV, provides high accuracy in recognizing text from images, including PDFs. This ensures that the extracted text is reliable and suitable for further processing in Excel.
- Flexibility: The Python programming language offers flexibility in integrating Tesseract OCR with other libraries like OpenCV for image preprocessing. This allows for customizations and optimizations tailored to specific requirements, enhancing the accuracy and efficiency of text extraction.
- Speed: Tesseract, being optimized for speed, enables swift text recognition even from large documents such as PDFs. This speed is crucial when processing numerous documents or large volumes of text, allowing for efficient importation into Excel.
- Open Source: Tesseract OCR, Pytesseract, and OpenCV are open-source libraries, making them freely available for commercial and non-commercial use. This eliminates the need for costly proprietary solutions, thereby reducing project expenses.
- Cross-platform Compatibility: Python, Tesseract, and OpenCV are compatible with various operating systems, including Windows, macOS, and Linux. This ensures that OCR solutions developed using these technologies can be deployed across different platforms without major modifications.
- Language Support: Tesseract supports a wide range of languages, making it suitable for extracting text from PDFs in different languages. This multi-language support is beneficial for businesses operating in multilingual environments, enabling them to handle documents in various languages seamlessly.
- Image Preprocessing: OpenCV provides extensive functionalities for image preprocessing, such as noise reduction, image enhancement, and binarization. These preprocessing techniques help improve the quality of input images, thereby enhancing the accuracy of OCR results.
- PDF Parsing: With the integration of PyPDF2 or other PDF parsing libraries, Python can extract text and metadata from PDF files, which can then be fed into the OCR pipeline. This enables seamless importation of PDF content into Excel sheets, facilitating data analysis and manipulation.
- Data Extraction: Once the text is extracted from PDFs using OCR, Python can parse and organize the data into a structured format suitable for Excel. This includes extracting tables, lists, and other structured content from the PDFs, preserving the original formatting for easy interpretation in Excel.
- Automation: By combining OCR with Python scripting, tasks such as importing PDF data into Excel can be automated, saving time and reducing manual effort. This automation is particularly beneficial for businesses dealing with a large volume of PDF documents regularly.In conclusion, leveraging OCR with Tesseract in Python using Pytesseract and OpenCV offers numerous benefits, including accuracy, flexibility, speed, cost-effectiveness, cross-platform compatibility, language support, image preprocessing capabilities, PDF parsing functionalities, data extraction, and automation. These advantages make it an ideal choice for importing PDF data into Excel and streamlining document processing workflows.
What benefits do open-source OCR tools offer?
Open Source OCR (Optical Character Recognition) tools are software programs that convert scanned images or text within images into machine-encoded text. They are invaluable for extracting text data from various sources like scanned documents, PDFs, or images. Open Source OCR tools are particularly popular due to their accessibility, flexibility, and often cost-effectiveness compared to proprietary alternatives. Below is a detailed description of Open Source OCR tools, covering their features, advantages, popular options, and how they work:
- Tesseract OCR: Developed by Google, Tesseract is one of the most widely used open-source OCR engines, known for its accuracy and language support.
- OCRopus: An OCR system focusing on the use of large-scale machine learning for text recognition, OCRopus offers advanced features such as layout analysis and document understanding.
- Cognitive OpenOCR: A modular and extensible OCR engine built on top of Tesseract, Cognitive OpenOCR provides additional functionality for document analysis and recognition.
- Ocrad: A simple and lightweight OCR engine primarily designed for recognizing machine-printed text in scanned documents.
- GImageReader: A graphical user interface (GUI) frontend for Tesseract OCR, gImageReader provides an intuitive interface for performing OCR tasks on scanned images or PDF files.
How can Tesseract OCR be optimized for accurate text recognition from low-quality images?
Tesseract OCR (Optical Character Recognition) is an open-source software tool primarily used for extracting text from images. Developed by Google, it is one of the most accurate and widely used OCR engines available. Tesseract is capable of recognizing various languages and fonts, making it a versatile solution for text recognition tasks.
Here’s a detailed breakdown of Tesseract OCR:
- Functionality: Tesseract OCR works by analyzing the patterns of light and dark pixels in an image to identify characters and words. It processes images in several stages, including preprocessing, text detection, character recognition, and post-processing.
- Preprocessing: Before text recognition can occur, Tesseract preprocesses the image to enhance its quality and improve OCR accuracy. This may involve tasks such as noise reduction, binarization (converting the image to black and white), skew correction (straightening tilted text), and de-speckling.
- Text Detection: Tesseract identifies regions of text within the image using techniques like connected component analysis and contour detection. It locates areas where text is present and extracts them for further processing.
- Character Recognition: Once the text regions are identified, Tesseract segments the image into individual characters and attempts to recognize each one. It utilizes machine learning algorithms, including deep neural networks, to match patterns and classify characters accurately.
- Language Support: Tesseract supports a wide range of languages, from commonly used ones like English, Spanish, and Chinese to less widely spoken languages. It also offers the capability to recognize multiple languages within the same document.
- Output: After processing the image, Tesseract outputs the recognized text in a plain text format, which can be further processed or used for various applications. Additionally, it may provide information about the confidence level of each recognized character or word.
- Accuracy: Tesseract is known for its high accuracy, especially when used with properly preprocessed images and trained language data. However, the accuracy can vary depending on factors such as image quality, font type, and language complexity.
Now, let’s integrate the keyword “accounts payable” into the content: Accounts payable departments in organizations often deal with a large volume of documents containing textual information, such as invoices, receipts, and purchase orders. Tesseract OCR can significantly streamline accounts payable processes by automating the extraction of text from these documents. For example, when processing invoices received from suppliers, Tesseract can accurately extract key information such as vendor names, invoice numbers, dates, and amounts payable. This extracted text can then be seamlessly integrated into accounting systems for further processing, reducing manual data entry errors and speeding up the payment approval workflow. By leveraging Tesseract OCR technology, accounts payable teams can improve efficiency, accuracy, and overall productivity in managing financial transactions.
How can one effectively install Tesseract for optimal performance and usage?
Tesseract is an open-source OCR (Optical Character Recognition) engine developed by Google. It is widely used for extracting text from images, making it a valuable tool for various applications such as document scanning, text extraction from images, and more. Here’s a general description of how to install Tesseract on different platforms:
- Linux: – Tesseract can typically be installed from the package manager of your Linux distribution. For example, on Ubuntu or Debian-based systems, you can use: sudo apt-get install tesseract-ocr – This command will install Tesseract along with its dependencies.
- macOS: – On macOS, you can install Tesseract using Homebrew, a popular package manager for macOS. First, make sure you have Homebrew installed, then run: brew install tesseract
– This command will download and install Tesseract and its dependencies.
- Windows:– On Windows, you can download an installer from the Tesseract GitHub releases page or use package managers like Chocolatey.
– To install via Chocolatey, if you have it installed, run: choco install tesseract
– If you prefer to download the installer directly, you can find it on the Tesseract GitHub releases page and follow the installation instructions provided.
Once installed, you can use Tesseract from the command line or integrate it into your applications via libraries or wrappers available in various programming languages such as Python, Java, C++, etc. Tesseract supports a wide range of image formats and languages, and you can specify these parameters when using it to extract text from images.
It’s worth noting that Tesseract installation may also involve additional language data files for improved accuracy in recognizing text from specific languages. These language data files can typically be downloaded separately and installed alongside Tesseract, depending on your requirements.
Always refer to the official Tesseract documentation or resources specific to your platform for the most up-to-date and detailed installation instructions.
"OCR Implementation Using Tesseract, Pytesseract, and OpenCV in Python"
What is the command line format for running Tesseract OCR?
Running Tesseract with Command Line Interface (CLI) allows users to perform Optical Character Recognition (OCR) tasks directly from the command line of their operating system. Tesseract is an open-source OCR engine maintained by Google, capable of recognizing text from various image formats.
To use Tesseract with CLI, users typically follow these steps:
- Installation: Tesseract needs to be installed on your system. Depending on your operating system, you can install it using package managers like apt (for Debian-based systems), Homebrew (for macOS), or by downloading the binaries from the Tesseract GitHub repository.
- Input Image: Prepare the image containing the text you want to extract. Supported formats include JPEG, PNG, TIFF, and others.
- Command Syntax: Invoke Tesseract from the command line, providing the input image file and specifying any desired options or language settings. For example:
tesseract input_image.png output_text
This command will extract text from `input_image.png` and save the result in a text file named `output_text.txt`.
- Options: Tesseract provides various options to enhance OCR accuracy or customize the output. These options can be specified in the command line, such as language selection (`-l`), OCR engine mode (`-oem`), page segmentation mode (`-psm`), and more.
- Output Handling: Once Tesseract completes OCR processing, the extracted text is typically saved to a text file specified in the command or printed directly to the console.
By running Tesseract with CLI, users can automate text extraction tasks, integrate OCR capabilities into scripts or workflows, and leverage its flexibility and reliability for a wide range of applications.
How does Pytesseract work with OpenCV for OCR?
Optical Character Recognition (OCR) with Pytesseract and OpenCV is a process that involves extracting text from images or scanned documents. Pytesseract is a Python wrapper for Google’s Tesseract OCR engine, while OpenCV is a popular library for computer vision tasks. Combining these two tools allows developers to perform OCR on images efficiently.
Here’s a brief description of the process:
- Image Preprocessing: Before performing OCR, it’s often necessary to preprocess the image to improve the accuracy of the OCR results. This may involve operations like resizing, converting to grayscale, noise reduction, and binarization.
- Text Detection: Using OpenCV, text regions can be detected within the image. This step involves identifying areas of the image where text is present.
- Text Recognition: Once text regions are identified, Pytesseract is used to extract the text from these regions. Pytesseract processes the text and returns the recognized text as a string.
- Post-processing: Optionally, post-processing steps can be applied to improve the accuracy of the extracted text. This might involve techniques like spell checking or language modeling.
- Output: Finally, the recognized text can be used for various purposes, such as data extraction, text analysis, or indexing.
Overall, OCR with Pytesseract and OpenCV is a powerful tool for extracting text from images, enabling automation and analysis of textual data from scanned documents, images, or screenshots.
What are the different modes of page segmentation?
Page segmentation modes refer to the different methods used by optical character recognition (OCR) software to analyze and segment text and images on a scanned page. These modes help OCR systems identify and extract meaningful content from documents. Here are some common page segmentation modes:
- Automatic (default): In this mode, the OCR software automatically determines the best segmentation method based on the content of the document. It tries to balance accuracy and speed by adapting its approach to the characteristics of each page.
- Single Block: This mode treats the entire page as a single block of text without attempting to segment it into smaller units. It’s useful for documents with simple layouts or when preserving the page’s original formatting is important.
- Single Column: This mode segments the page into individual columns of text. It’s suitable for documents with a single column layout, such as newspapers or academic articles.
- Single Line: Here, the OCR software segments the page into individual lines of text. This mode is beneficial for documents with narrow columns or when dealing with text laid out horizontally.
- Single Word: In this mode, the page is segmented into individual words. It’s helpful for extracting text from documents with complex layouts or when precise word-level recognition is required.
- Sparse Text: This mode identifies and extracts text from documents with a sparse layout, such as forms or tables, where text is scattered across the page with significant whitespace in between.
- Raw Image: This mode treats the entire page as a single image without attempting any text segmentation. It’s useful when the document contains non-text elements like graphics or diagrams that need to be preserved in their original form.
Each segmentation mode has its advantages and is suitable for different types of documents. The choice of mode depends on factors such as the complexity of the document layout, the desired level of text granularity, and the specific requirements of the OCR task.
How can AI accurately detect text orientation and script?
Detecting orientation and script refers to the process of determining the direction (orientation) and writing system (script) of a given text. This task is crucial in various natural language processing (NLP) applications, such as optical character recognition (OCR), language translation, and text-to-speech synthesis.
The orientation detection aspect involves identifying whether the text is written horizontally (left-to-right or right-to-left) or vertically (top-to-bottom). This information is essential for correctly interpreting and processing the text.
Script detection involves identifying the writing system used in the text, such as Latin script (used for English, Spanish, etc.), Cyrillic script (used for Russian, Bulgarian, etc.), Arabic script, Chinese characters, and so on. Accurate script detection is necessary for performing language-specific processing tasks, such as language identification, text normalization, and sentiment analysis.
Algorithms for orientation and script detection typically involve analyzing the arrangement and shapes of characters, as well as statistical properties of the text, to make accurate predictions. Machine learning techniques, including neural networks, are commonly employed for this purpose, utilizing annotated datasets to train models capable of recognizing various orientations and scripts.
Can you design a regular expression pattern to detect only digits in a given string?
Detecting only digits refers to the process of identifying and extracting numerical characters from a given text or input. This task involves parsing through a string of characters and isolating those that represent numerical values, such as 0-9. This process is commonly used in various applications such as data validation, text processing, and natural language processing tasks where numerical information needs to be extracted or processed separately from other types of data.
Using tessdata_fast
Using tessdata_fast refers to utilizing a specific configuration or version of Tesseract OCR’s data files for faster text recognition. Tesseract OCR (Optical Character Recognition) is a popular open-source tool for extracting text from images. The tessdata_fast mode includes pre-trained data files optimized for speed, sacrificing some accuracy compared to the standard tessdata files. This mode is particularly useful in scenarios where speed is prioritized over absolute accuracy, such as real-time applications or large-scale document processing tasks. By using tessdata_fast, users can achieve faster text recognition performance while still maintaining acceptable accuracy levels for their specific use cases.
Training Tesseract on custom data
Training Tesseract on custom data involves teaching the Tesseract Optical Character Recognition (OCR) engine to recognize specific fonts, symbols, or languages that are not included in its default training data. This process is crucial for improving OCR accuracy when dealing with unique or specialized content.
To train Tesseract on custom data, you typically follow these steps:
- Data Preparation: Gather a sizable amount of high-quality training data that represents the fonts, symbols, or languages you want to recognize. This data should include a variety of text samples, fonts, sizes, styles, and orientations.
- Labeling: Manually annotate the training data to provide ground truth labels for the text. This involves specifying the exact text content present in each image along with its corresponding location.
- Training Data Generation: Convert the labeled data into a format that Tesseract can use for training. This often involves creating training data files in the Tesseract-compatible format, such as Tesseract’s box file format.
- Training: Use Tesseract’s training tools to train the OCR engine on the custom data. This process involves feeding the labeled training data to Tesseract and allowing it to adjust its internal parameters to better recognize the provided text patterns.
- Evaluation: Assess the performance of the trained model using validation data that was not used during training. This helps identify areas where the OCR engine may still struggle and provides insight into potential improvements.
- Iterative Improvement: Fine-tune the trained model based on the evaluation results and repeat the training process if necessary. This iterative approach helps refine the OCR engine’s performance over time.
- Integration: Once satisfied with the performance, integrate the trained model into your application or workflow to leverage its improved recognition capabilities.
Training Tesseract on custom data can significantly enhance its ability to accurately recognize text in specific contexts, making it a valuable tool for various OCR applications. However, it requires careful data curation, training, and evaluation to achieve optimal results.
Limitations of Tesseract
Tesseract is an open source Optical Character Recognition (OCR) engine maintained by Google. While it’s widely used and constantly improving, it does have some limitations:
- Accuracy with Handwritten Text: Tesseract struggles with recognizing handwritten text, especially if the handwriting is messy or unconventional.
- Complex Document Layouts: Documents with complex layouts, multiple columns, or intricate formatting can pose challenges for Tesseract. It may not accurately extract text in such cases.
- Non-Latin Scripts: While Tesseract supports various languages, its performance with non-Latin scripts, such as Arabic, Chinese, or Devanagari, might not be as accurate as with Latin scripts.
- Poor Image Quality: Tesseract’s accuracy heavily depends on the quality of the input image. Blurry, skewed, or low-resolution images can lead to errors in text recognition.
- Need for Preprocessing: Tesseract often requires preprocessing steps such as image binarization, noise reduction, and deskewing to improve accuracy, especially for challenging input images.
- Limited Support for Tables and Graphics: Tesseract may not accurately extract tabular data or graphical elements from documents, as it primarily focuses on recognizing text.
- Resource Intensive for Training: While Tesseract can be trained for specific use cases, the process is resource-intensive and requires expertise in machine learning and OCR.
Despite these limitations, Tesseract remains a popular choice for OCR tasks due to its open-source nature, continuous development, and broad language support. Users often combine it with other tools and techniques to mitigate its limitations and achieve better results for specific use cases.
"OCR in Python: Pytesseract, OpenCV, Tesseract. Maximize your code. Transform your projects. Dive in now!"
OCR with SDLCCORP
OCR (Optical Character Recognition) with SDLCCORP involves utilizing SDLCCORP’s OCR technology to convert images of text into machine-readable text. SDLCCORP is likely a company or a software solution that provides OCR services or software.
Here’s a brief description of how OCR with SDLCCORP works:
- Image Input: Users provide SDLCCORP with images containing text that needs to be converted. These images could be scanned documents, photographs, or screenshots.
- Preprocessing: The images undergo preprocessing to enhance their quality and improve OCR accuracy. This may involve tasks like noise reduction, image binarization, and deskewing.
- Text Recognition: SDLCCORP’s OCR engine analyzes the preprocessed images and identifies individual characters and words using pattern recognition algorithms. This process involves segmenting the text, identifying characters, and matching them to a database of known characters.
- Text Output: The recognized text is then extracted and outputted in a machine-readable format, such as plain text, PDF, or HTML. Depending on the user’s needs, SDLCCORP may also provide options for formatting and structuring the outputted text.
- Post-Processing: Users may have the option to review and edit the recognized text if needed. Additionally, post-processing techniques may be applied to further improve accuracy and readability.
Overall, OCR with SDLCCORP streamlines the process of digitizing text from images, enabling users to efficiently convert physical documents into editable and searchable digital formats.
Conclusion
In conclusion, leveraging Tesseract OCR in Python with Pytesseract and OpenCV provides a robust and flexible solution for extracting text from images. By combining the powerful text recognition capabilities of Tesseract with the image processing functionalities of OpenCV, users can achieve accurate results across a wide range of applications. Whether digitizing documents, extracting data from images, or automating text recognition tasks, this approach offers efficiency and reliability.
Additionally, incorporating PayPal wire transfer as a keyword in the content underscores the diverse applications of OCR technology. Businesses and individuals can utilize OCR to streamline financial processes, such as extracting transaction details from wire transfer receipts or invoices. By integrating OCR with payment systems like PayPal, users can automate data entry, enhance accuracy, and improve the overall efficiency of financial operations.
Overall, mastering OCR with Tesseract in Python alongside Pytesseract and OpenCV empowers users to unlock the full potential of text recognition technology, offering countless opportunities for automation, data extraction, and process optimization in various domains, including finance and beyond.
How do I install Tesseract and Pytesseract on my system for Python?
How can I use Tesseract OCR with Pytesseract in Python?
What image preprocessing techniques can I apply with OpenCV before OCR?
How do I handle multiple languages or specific language recognition with Tesseract OCR in Python?
5. How can I improve OCR accuracy when dealing with challenging images or fonts?
FAQs
Share a few details about your project, and we’ll get back to you soon.
Let's Talk About Your Project
- Free Consultation
- 24/7 Experts Support
- On-Time Delivery
- sales@sdlccorp.com
- +1(510-630-6507)